Athena에서 Apache Iceberg 테이블 활용하기(1)
Athena에서 Apache Iceberg 테이블 활용하는 법에 대해 간단히 정리한다.
Apache Iceberg는 The open table format for analytic datasets 이다.
자세한 설명은 https://aws.amazon.com/ko/what-is/apache-iceberg/에서 확인할 수 있다.
참고로, Athena로는 Iceberg 활용에 제한이 있다. Considerations and limitations - in AWS
Iceberg 테이블 생성
기본 테이블 정의
기존 EXTERNAL 테이블과 다른 점
- 테이블 생성 시 EXTERNAL 생략
- 파티션 컬럼은 테이블에 컬럼 먼저 정의 후 사용
- tinyint, smallint 대신 int 사용 ( Iceberg는 tinyint, smallint 자체를 지원하지 않음 )
타입에 대한 자세한 내용은 아래에서 확인할 수 있다.
Supported data types for Iceberg tables in Athena - in AWS
CREATE TABLE [ DB ].[ 테이블 ] (
A string,
B int,
[파티션 컬럼] date
)
PARTITIONED BY ([파티션 컬럼])
LOCATION 's3://[ 버킷 ]/[ PREFIX ]'
TBLPROPERTIES (
'table_type'='iceberg'
)
CTAS 활용
기존에 사용하던 EXTERNAL 테이블을 Iceberg 테이블로 쉽게 변환할 수도 있다.
주의할 점은 Iceberg에서 지원하지 않는 타입은 CAST를 통해 타입 변환을 해야 하고
파티션이 되는 컬럼도 SELECT 문에 포함되어야 한다. ( SELECT * 사용 시 주의 )
가장 주의해야 할 점은 CTAS는 최대 100개의 파티션 처리만 가능하다. CTAS partition limit - in AWS
Migrating existing tables to Iceberg - in AWS 다음 글에서 자세한 마이그레이션 방법을 안내하고 있다.
CREATE TABLE [ DB ].[ 테이블 ]
WITH (
table_type ='ICEBERG', is_external = false, partitioning = ARRAY['파티션1'],
location ='s3://[ 버킷 ]/[ PREFIX ]'
)
AS SELECT ..., CAST(컬럼2 AS int) AS 컬럼2, 파티션1 FROM [ 테이블 ]
Iceberg 테이블 구조
자세한 Spec은 Iceberg Table Spec에서 확인할 수 있다.
메타데이터는 metadata, 데이터는 data 폴더(prefix)에 저장된다. CREATE TABLE 실행 시 최초 metadata 파일이 하나 생긴다.
주요 용어 : https://iceberg.apache.org/spec/#terms
- Schema – Names and types of fields in a table.
- Partition spec – A definition of how partition values are derived from data fields.
- Snapshot – The state of a table at some point in time, including the set of all data files.
- Manifest list – A file that lists manifest files; one per snapshot.
- Manifest – A file that lists data or delete files; a subset of a snapshot.
- Data file – A file that contains rows of a table.
- Delete file – A file that encodes rows of a table that are deleted by position or data values.
아래 그림에서 간단한 구조를 잘 설명해놓았다.
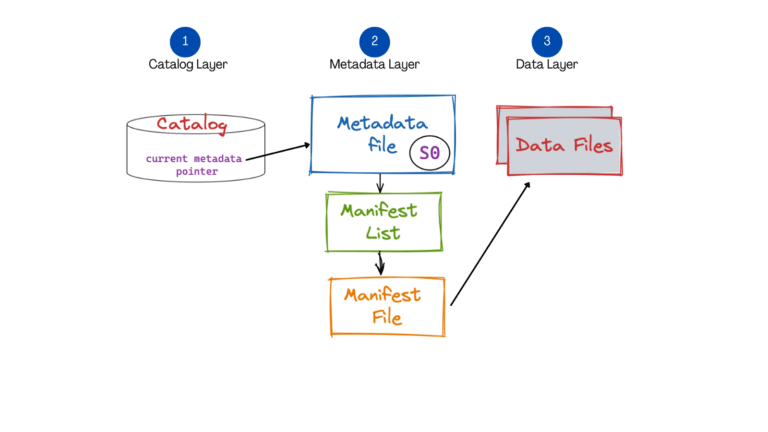
출처: A Hands-On Look at the Structure of an Apache Iceberg Table - by dremio
CRUD 실행마다 하나의 메타데이터 파일이 생기며, 하나의 메타데이터는 누적된 snapshot을 포함한다. (누적 snapshot은 설정에 따라 다름)
하나의 snapshot은 하나의 Manifest 리스트 파일을 가지고 있고 이 리스트에는 여러 Manifest 파일 정보를 가지고 있다.
하나의 Manifest 파일은 여러 Data 파일에 대한 정보를 가지고 있다.
간편한 테이블 관리
기존 아테나 테이블은 ALTER TABLE ADD PARTITION으로 파티션을 매일 추가해주어야 하고
컬럼 추가/삭제가 필요할 경우 테이블을 재정의 후 MSCK REPAIR TABLE로 파티션을 다시 스캔하는 작업까지 해야 했다.
Iceberg 테이블은 컬럼 추가/삭제 등의 DDL 기능을 제공하고 파티션도 자동으로 인식한다.
단, 빅쿼리와 같이 파티션을 강제하는 쿼리 옵션은 없기 때문에 주의는 필요하다.
간단한 CRUD TEST
INSERT
CREATE TABLE 문을 실행하면 0번 메타데이터 파일만 생기고 INSERT 문을 실행 후에 1번 메타데이터, manifest-list 파일, manifest 파일이 생겼다.
manifest-list : snap-[…].avro 형태의 파일
manifest : […]-m[숫자].avro 형태의 파일

생성된 메타데이터를 보면 snapshot ID와 manifest 정보를 알 수 있다.
"current-snapshot-id" : 7360679585492358774,
...
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 7360679585492358774,
"timestamp-ms" : 1722354250176,
"summary" : {
"operation" : "append",
"added-data-files" : "3",
"added-records" : "5",
"added-files-size" : "1544",
"changed-partition-count" : "3",
"total-records" : "5",
"total-files-size" : "1544",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://[버킷]/[PREFIX]/metadata/snap-7360679585492358774-1-c48d5e5e-6bff-45df-ab35-1a6cafa99cc7.avro",
"schema-id" : 0
} ]
data 폴더를 확인해보면 파티션 기준에 따라 폴더가 나뉘는데 랜덤문자열 형태의 prefix가 추가된다.
이는 데이터를 균일하게 분포시켜 성능을 높이기 위한 특징이라고 한다. ( ChatGPT 참고)
data/ Fp29RQ/ part_date=2024-01-01/ .parquet
data/ lYLh2g/ part_date=2024-01-02/ .parquet
data/ nrOJaw/ part_date=2024-01-03/ .parquet
테스트용 데이터
| part_date | part_name | part_val |
|---|---|---|
| 1/1/24 | A | 10 |
| 1/2/24 | A | 20 |
| 1/3/24 | A | 30 |
| 1/1/24 | B | 5 |
| 1/2/24 | B | 10 |
SELECT
( 다른 테이블 ) SELECT 쿼리 후 cloudtrail을 통해 S3 Operation을 확인해봤다.
메타데이터를 읽고 메니페스트 리스트 파일을 Head로 한 번 체크 후 읽는다. 그 뒤로 메니페스트 파일과 데이터 파일을 읽는다.
아테나의 병렬 처리를 위해 각 워커마다 파일을 읽기 때문에 중복 호출이 되는 듯하다. INSERT, UPDATE, DELETE 시에는 PutObject가 추가된다.
| EVENT | PARAMETER |
|---|---|
| GetObject | “key”:”/metadata/00002-b5fb77ca-d8b7-4d87-8941-ea4293d3a061.metadata.json |
| HeadObject | “key”:”/metadata/snap-3679114384697091363-1-ed52d999-0f54-49f1-a3a1-254bee758fe5.avro” |
| GetObject | “key”:”/metadata/snap-3679114384697091363-1-ed52d999-0f54-49f1-a3a1-254bee758fe5.avro” |
| GetObject | “key”:”/metadata/cf59be8f-ed0b-4c22-94d2-1db2f01a52bf-m0.avro” |
| GetObject | “key”:”/metadata/cf59be8f-ed0b-4c22-94d2-1db2f01a52bf-m0.avro” |
| GetObject | “key”:”/metadata/ed52d999-0f54-49f1-a3a1-254bee758fe5-m0.avro” |
| GetObject | “key”:”/metadata/ed52d999-0f54-49f1-a3a1-254bee758fe5-m0.avro” |
| GetObject | “key”:”/data/322KlQ/part_date=2024-01-01/20240722_155029_00056_yihkx-a537b2fa-2bfb-42e5-a99b-23cfc24e9ac8.parquet” |
| GetObject | “key”:”/data/ingodQ/part_date=2024-01-02/20240722_154801_00134_g3kw7-e35f7162-bb65-413f-a217-55d27b94b936.parquet” |
| GetObject | “key”:”/data/mVUj9g/part_date=2024-01-01/20240722_154801_00134_g3kw7-7b68f2f0-bc89-4296-903e-c96dbea58b9e.parquet” |
| GetObject | “key”:”/data/rgPFWw/part_date=2024-01-02/20240722_155029_00056_yihkx-1acd6586-ac72-4723-8c27-b0218a967b19.parquet” |
UPDATE & DELETE
UPDATE default.iceberg_test SET part_val = part_val*10 WHERE part_name = 'A'
UPDATE 결과
| part_date | part_name | part_val |
|---|---|---|
| 1/1/24 | A | 100 |
| 1/2/24 | A | 200 |
| 1/3/24 | A | 300 |
| 1/1/24 | B | 5 |
| 1/2/24 | B | 10 |
새로 생긴 2번 메타데이터를 확인해보면 overwrite operation을 확인할 수 있다.
"snapshots" : [
{"sequence-number" : 1, ... },
{ "sequence-number" : 2,
"snapshot-id" : 3806108608147941901,
"parent-snapshot-id" : 7360679585492358774,
"timestamp-ms" : 1722355439523,
"summary" : {
"operation" : "overwrite",
...
},
...
]
manifest-list 파일을 확인해 보니 overwrite 동작에 대한 간단한 확인이 가능했다. sequence_number 2를 보면 content 값이 0인 상태와 1인 상태가 존재한다.
0은 데이터를 의미하며 1은 삭제를 의미한다.
| manifest_path | content | sequence_number | added_rows_count |
|---|---|---|---|
| …-m0.avro | 0 | 1 | 5 |
| …-m0.avro | 0 | 2 | 3 |
| …-m1.avro | 1 | 2 | 3 |
실제로 manifest file을 확인해보면 content 0에 해당하는 parquet 파일은 UPDATE된 데이터를 담고 있고
content 1인 경우 다음과 같이 파일명과 pos 값을 가지고 있다. 이는 이 파일의 pos 0인 값을 지우라는 뜻이다. ( 실제 삭제는 아님 )
DELETE + INSERT 방식으로 동작한다는 것을 확인할 수 있다.
| file_path | pos |
|---|---|
| ../part_date=2024-01-02/[…].parquet | 0 |
위와 같은 방식을 position delete 방식이리 한다. ( 반대로 equality delete 방식이 있다. ) Trino - row-level-deletion
equality delete 방식은 parquet 파일에 삭제할 컬럼과 value 정보를 저장한다.
( 배치 처리가 대부분이라 읽기 성능을 우선으로 생각해서 선택한 것이 아닌가 생각한다. 실시간 처리가 가능한 오픈소스들은 equality delete 기능을 지원한다. )
이전 스냅샷의 데이터를 모두 읽은 뒤 pos로 지정된 데이터는 숨기고 새로 추가된 데이터를 보여준다.
이렇게 파일을 통합해서 읽는 방식을 MOR(Merge On Read)라고 한다. 반대로는 COW(Copy On Write) 방식이 있다.
스냅샷 생성 시 새로운 데이터 파일을 만드는 방식이다. 쓰기 성능이 중요하면 MOR, 읽기 성능이 중요하면 COW 방식을 사용할 수 있는데
기본적으로는 MOR 방식을 사용한다.
이렇게 복잡해보이는 이유는 History를 관리하여 Iceberg 타입의 time travel 기능을 수행하기 위해서이다.
UPDATE가 되기 이전 값은 이전 스냅샷의 데이터만 읽으면 간단하다.
DELETE의 방식은 새로 추가된 데이터만 제외하면 UPDATE 방식과 같다. 자세한 Manifest에 대한 정보는 이곳에서 확인할 수 있다.
Iceberg Table Spec - Manifests
References :