Athena에서 Apache Iceberg 테이블 활용하기(2)
Athena에서 Apache Iceberg 테이블 활용하는 법에 대해 간단히 정리한다.
TIME TRAVEL & ROLLBACK
Iceberg는 시간 또는 SNAPSHOT 버전 기준으로 과거의 데이터를 조회할 수 있다.
스냅샷 정보는 메타데이터 쿼리로 확인할 수 있다.
SELECT * FROM "iceberg_test$snapshots"
-- 간단하게 조회
SELECT * FROM "iceberg_test$history"
스냅샷 생성 시 어떤 작업(operation)을 수행했는 지에 대한 정보를 알 수 있다.
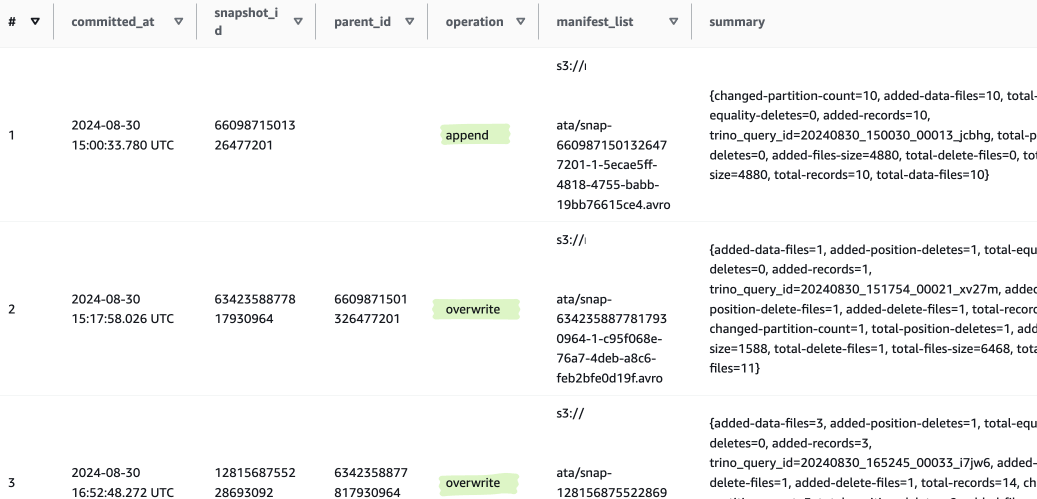
이 SNAPSHOT ID를 통해 데이터를 조회할 수 있다.
SELECT * FROM iceberg_test FOR VERSION AS OF 6609871501326477201
SELECT * FROM iceberg_test FOR TIMESTAMP AS OF TIMESTAMP '2020-01-01 10:00:00 UTC'
타임스탬프 기준으로도 조회가 가능하나 타임스탬프는 어떤 스냅샷 버전을 가리키는 지 정확히 알기 어렵기 때문에
스냅샷 ID 기준으로 조회하는 것을 권장하는 것 같기도 하다.
아쉽게도 아직 아테나 쿼리로 ROLLBACK 기능은 제공하지 않는 것으로 보인다.
다음 글을 보면 메타데이터 파일 삭제 등과 같은 이슈로 테이블 쿼리에 문제가 있는 경우 Spark를 통해 ROLLBACK을 수행해야 한다는 점을 알 수 있다.
How can I troubleshoot Apache Iceberg table errors with Athena?
스냅샷 관리 (최적화)
스냅샷 보관 기준 사용되지 않는 데이터를 정리하기 위해 VACUUM 명령어를 사용할 수 있다.
테이블의 기본 스냅샷 보관 기준은 432000초(5일)이다. 이 설정은 테이블 생성 시에도 적용할 수 있다.
ALTER TABLE iceberg_table SET TBLPROPERTIES (
'vacuum_max_snapshot_age_seconds'='432000'
)
VACUUM을 실행하면 보관 기준에 해당하는 스냅샷에서 사용하지 않는 데이터를 삭제해 저장 용량을 줄일 수 있다. (생각보다 시간이 오래 걸림)
VACUUM iceberg_test
참고 : 스냅샷이 많거나 수정, 삭제를 통해 파일 구조가 복잡할 경우 여러 번 VACUUM을 실행해야 효과를 볼 수 있다는 글이 있다.
ICEBERG_VACUUM_MORE_RUNS_NEEDED
MERGE ( UPSERT )
Iceberg 테이블에서 UPSERT를 구현하려면 Oracle과 같은 MERGE INTO 문을 사용한다.
MERGE 쿼리 기본 형식은 다음과 같다.
ON [ ... ] : 중복 조건에 대한 정의 (조건이 여러 개라면 파티션 컬럼을 먼저 작성한다.)
WHEN MATCHED : 중복 조건에 해당하는 경우
WHEN NOT MATCHED : 중복 조건에 해당하지 않는 경우
iceberg_test : MERGE 대상 테이블 - target
iceberg_for_merge : 추가할 데이터 테이블 - merge_table
MERGE INTO iceberg_test AS target USING (
SELECT *
FROM iceberg_for_merge
) AS merge_table
ON target.part_date = merge_table.part_date
WHEN MATCHED THEN
UPDATE SET
컬럼1 = merge_table.컬럼1,
컬럼2 = merge_table.컬럼2,
...
WHEN NOT MATCHED THEN
INSERT (
컬럼1,
컬럼2,
...
)
VALUES (
merge_table.컬럼1,
merge_table.컬럼2,
...
)
WHEN MATCHED 또는 WHEN NOT MATCHED 조건은 둘 중 하나만 사용해도 상관없다.
WHEN MATCHED ONLY : 중복 대상만 UPDATE
WHEN NOT MATCHED ONLY : 중복은 IGNORE(제외) 후 INSERT
참고 : 테이블 사이즈가 커질수록 데이터 사용량이 비례해서 증가하는 지 확인해 볼 필요가 있다.
( 테스트했을 때 테이블 사이즈와 비례하게 데이터 사용량이 증가했었으나 현재는 개선된 것으로 보임(?) )
OPTIMIZE
UPDATE, DELETE, MERGE를 많이 사용하면 데이터 파일 구조가 복잡해지고 병렬처리하면 데이터가 많이 분산 저장되기도 한다.
OPTIMIZE 쿼리는 파티션 기준에 대해 데이터를 압축 및 파일 수를 조정하여 최적화하는 역할을 한다.
OPTIMIZE iceberg_test REWRITE DATA USING BIN_PACK
WHERE [ 파티션 조건 ]
테이블 속성의 optimize_rewrite_data_file_threshold, optimize_rewrite_delete_file_threshold 값(파일의 개수)을 통해
최적화 수행에 대한 임계치를 정할 수 있다.
References :