pandas보다 빠르게 데이터 저장하기
pandas보다 데이터를 빠르게 저장하는 법에 대해 간단히 정리한다.
pandas를 편해서 사용하다 보니 생각보다 I/O 작업에 시간이 오래 걸린다.
이 방법들은 메모리를 초과하지 않는 데이터와 싱글 머신에서 유용하게 사용할 수 있다.
Big Sales Data - in Kaggle의 Books_rating.csv 2.86GB의 데이터를 가지고 성능을 비교해보았다.
| 테스트 대상 | 버전 |
|---|---|
| OS | ubuntu 22.04 |
| CPU | i7-12700 |
| python | 3.11 |
| pandas | 2.2.3 |
| pyarrow | 17.0.0 |
| duckdb | 1.1.1 |
| polars | 1.9.0 |
여기서는, pandas로 전처리가 된 상황을 가정하고 진행했다.
데이터 타입은 자동으로 설정되는 그대로 사용했다. 데이터 타입 최적화에 따라 성능은 달라질 수 있을 것으로 보인다.
테스트 대상 모두 Apache Arrow을 지원하기 때문에 데이터 호환이 가능하다.
CSV OUTPUT
데이터 로딩(pandas)
df_pd = pd.read_csv('../dataset/Books_rating.csv')
결과 : 13.4 s ± 34 ms per loop
df_pd pandas 데이터프레임 로딩 이후,
pandas
df_pd.to_csv('./pandas_output.csv', index=False)
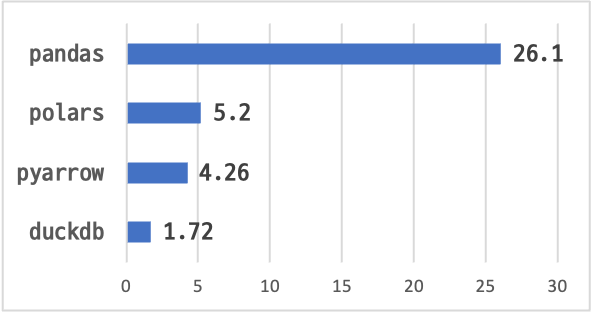
결과 : 26.1 s ± 26.5 ms per loop
polars
import polars as pl
df_pl = pl.from_pandas(df_pd)
df_pl.write_csv("polars_output.csv")
결과 : 5.2 s ± 271 ms per loop
pyarrow
import pyarrow as pa
import pyarrow.csv as csv
table_pa = pa.Table.from_pandas(df_pd)
csv.write_csv(table_pa, 'pyarrow_output.csv')
결과 : 4.26 s ± 683 ms per loop
정렬이 필요한 경우,
sorted_table_pa = table_pa.sort_by([('profileName', 'ascending'), ('review/time','descending')])
참고
엑셀로 csv파일을 열 때, utf8로 저장된 한글을 읽을 수 있는 방법으로 codecs.BOM_UTF8을 활용한다.
import codecs
table_pa = pa.Table.from_pandas(df_pd)
with open('./pyarrow_output_utf8.csv', 'wb') as f:
with io.BytesIO() as csv_buffer:
csv_buffer.write(codecs.BOM_UTF8)
csv.write_csv(table_pa, csv_buffer)
f.write(csv_buffer.getvalue())
결과 : 5.48 s ± 781 ms per loop
duckdb
df_pd 변수를 그대로 활용 가능
import duckdb
ddb_conn = duckdb.connect()
ddb_conn.sql(f"""
COPY df_pd TO './duckdb_output.csv' (HEADER, DELIMITER ',');
""")
결과 : 1.72 s ± 141 ms per loop
결과 요약
EXCEL OUTPUT
참고로, 엑셀파일로 저장하기 위해서는 각각 추가 패키지 설치가 필요하다.
데이터 로딩(pandas)
엑셀 시트 행 개수 제한이 있어 백만 개로 필터링 후 비교했다.
df_pd_mili = df_pd.iloc[:1000000]
pandas
#!pip install XlsxWriter==3.2.0
df_pd_mili.to_excel('./pandas_excel.xlsx', index=False)
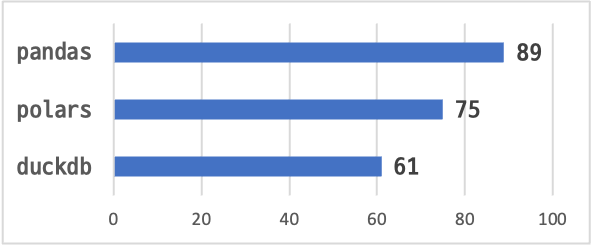
결과 : 1min 29s ± 319 ms per loop
polars
#!pip install XlsxWriter==3.2.0
df_pl_mili = pl.from_pandas(df_pd_mili)
df_pl_mili.write_excel("polars_excel.xlsx")
결과 : 1min 15s ± 144 ms per loop
duckdb
ddb_conn.sql(f"""
INSTALL spatial;
LOAD spatial;
""")
ddb_conn.sql(f"""
COPY df_pd_mili TO 'duckdb_excel.xlsx' WITH (FORMAT GDAL, DRIVER 'xlsx');
""")
결과 : 1min 1s ± 81.5 ms per loop
duckdb는 SQL 문 ORDER BY로 정렬을 쉽게 구현할 수 있다.
결과 요약
참고 : 로딩 후 pandas df로 비교
polars
df_pl = pl.read_csv('../dataset/Books_rating.csv')
df_pd_from_pl = df_pl.to_pandas()
결과 : 7.58 s ± 170 ms per loop
duckdb
ddb_conn.sql(f"""
CREATE OR REPLACE TABLE table_ddb AS SELECT * FROM read_csv_auto('../dataset/Books_rating.csv', header = true);
""")
df_pd_from_ddb = ddb_conn.sql(f"""
SELECT * FROM table_ddb
""").df()
결과 : 3.33 s ± 277 ms per loop
결론
단순히 사용하기에는 duckdb로 전환하는 게 가장 효과적인 것으로 보인다.
간단히는 pyarrow를 활용해서 기존 코드를 약간만 수정해도 빠른 성능을 기대할 수는 있다.
polars는 잘 사용해보지 않았지만 아래 자료를 보면 duckdb보다 빠르다는 자료도 있다.
References :