Vector by datadog 사용기 ( with k8s )
Vector by datadog 사용한 후기를 간단히 정리한다.
Vector는 A lightweight, ultra-fast tool for building observability pipelines라고 한다.
수집, 가공, 전송까지 모두 다 가능하기에 end-to-end platform이라고도 한다.
개요
데이터홀릭 유튜브를 시청하다가 Vector라는 오픈소스를 알게 되었고 로그 수집기로 사용한다는 것을 알게 되었다
그래서 살펴보니 실제로 내가 원하는 구현 방식이 가능해 보였다. 바로 Stream Consumer 기능이다.
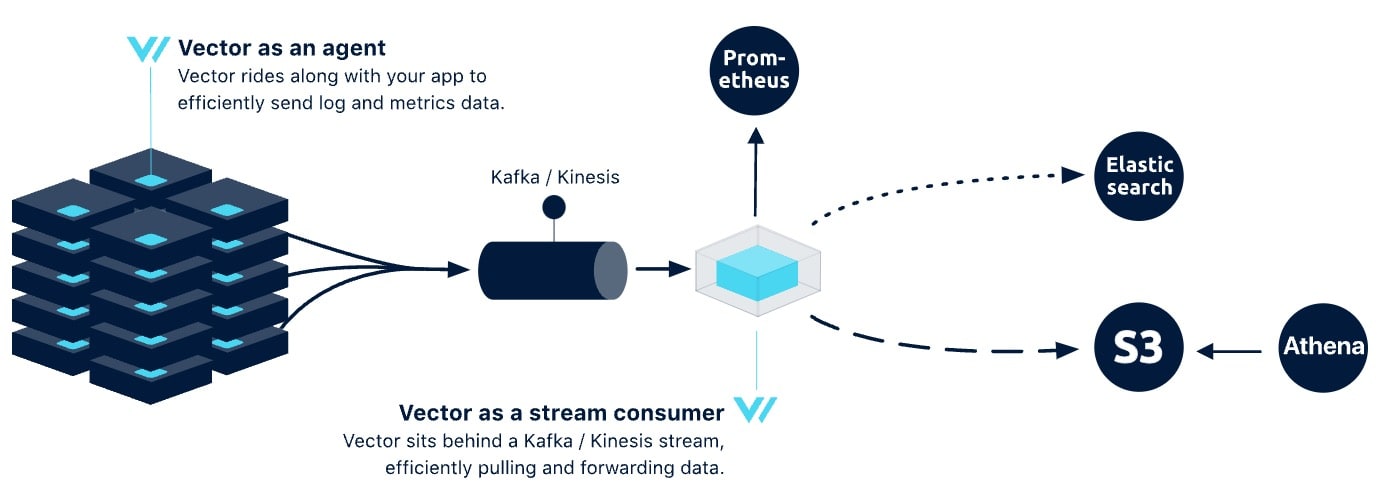
출처 : https://vector.dev/docs/setup/deployment/topologies/#stream-based
현재 사용하고 있는 방식은 데이터 수집 비용이 좀 나가는 편이다. 구조를 살펴보면
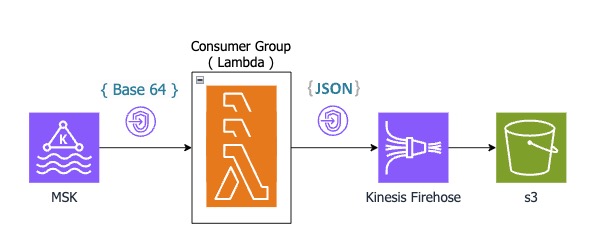
운영 이슈를 피하기 위해 Lambda consumer를 도입했고 Firehose로 데이터를 S3에 저장한다. 운영이 편한 만큼 비용이 따른다.
MSK -> Lambda / Lambda -> Firehose 로 데이터를 보낼 때 VPC Endpoint를 사용한다.
NAT 사용 시보다 1/6 가격이지만 같은 가용 영역끼리 통신 시 무료인 혜택을 받지 못한다.
MSK에서 Lambda API로 데이터를 전송하기 위해 Base64 인코딩을 하기 때문에 데이터 사이즈가 증가하고
Firehose는 JSON 타입의 데이터를 받기 때문에 많은 데이터 사이즈 비용이 추가된다.
Consumer가 DB 또는 레디스와의 통신이 필요없는 경우라면 Vector가 Consumer + Firehose 역할을 대신할 수 있어보였다.
vector aggregator & pipeline
Vector는 Agent(single-host에서 수집) 또는 Aggreagtor(cross-host에서 수집) 역할로 배포할 수 있다.
여기서는 Kafka로부터 데이터를 수집하기 때문에 Aggreagtor를 활용한다.
참고 : Deployment roles
vector-operator 설치
Vector를 k8s에 쉽게 배포하기 위한 operator가 존재했다. ( 공식 operator는 아님 )
기본적으로 모든 namespace를 체크하며 values.yaml을 수정하여 namespace를 지정할 수도 있다.
Aggregator로 POD이 배포되고 Pipeline으로 처리 로직이 배포된다.
vector aggregator
배포에 대한 기본 자료 : vector-operator/docs/aggregator.md
환경변수에 대한 설명은 여기에 나와있다. Vector Environment variables
VECTOR_GRACEFUL_SHUTDOWN_LIMIT_SECS의 경우, aggregator 또는 pipeline의 업데이트가 있을 때
새로운 데이터 수신을 중단하고 현재 처리 중인 이벤트들을 완료할 여유 시간을 주기 위한 설정이다.
하지만, Vector에는 acknowledgements 기능으로 데이터 처리 여부를 체크 후 재시도를 할 수 있다. ( pipeline에서 정의 )
상호보완적으로 사용할 수 있을 거 같다.
배포 yaml
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorAggregator
metadata:
name: yahwang-consumer-detect-aggregator
namespace: platform
spec:
image: timberio/vector:0.43.1-debian
# imagePullSecrets:
# - name: docker-registry
replicas: 2
env:
- name: VECTOR_THREADS
value: "2"
- name: VECTOR_LOG
value: "INFO"
- name: VECTOR_GRACEFUL_SHUTDOWN_LIMIT_SECS
value: "180"
- name: AWS_ACCESS_KEY_ID
value: "..."
- name: AWS_SECRET_ACCESS_KEY
value: "...."
dataDir: /vector-data-dir # 디스크 버퍼 및 상태 관리
api:
enabled: true
resources:
requests:
memory: "500Mi"
cpu: "0.5"
limits:
memory: "1Gi"
cpu: "1"
vector pipeline
아래 그림에 나와있는 것처럼 Source - Transform - Sink 3단계로 나누어 데이터를 처리한다.
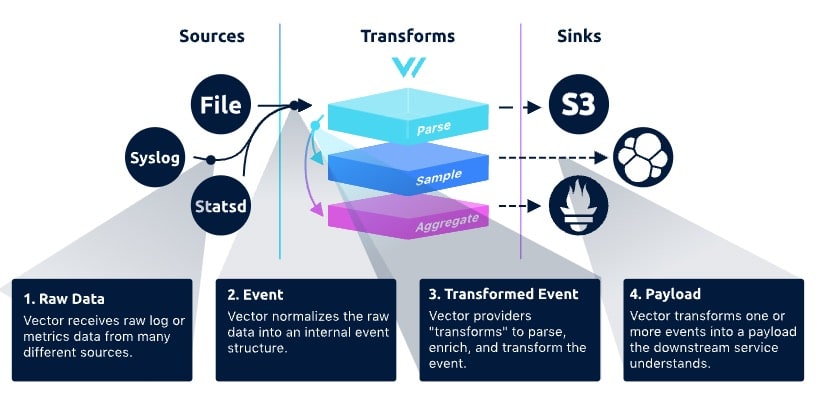
출처 : https://vector.dev/docs/about/under-the-hood/architecture/data-model/
source
kafka의 경우, 설정은 다른 서비스 사용 시와 비슷하게 설정할 수 있다. 데이터 타입 별로 decoding 설정이 필요하다.
transform
vector에서 데이터는 event라고 표현한다. decoding하면 event로 변환되고 이 event를 가공할 수 있다.
Vector Remap Language (VRL) 언어로 데이터를 가공할 수 있다.
예시로, del(.필드명)로 필요없는 필드를 삭제할 수 있다. 사용 가능한 함수는 아래 References에서 확인할 수 있다.
함수를 보면 두 가지 타입을 확인할 수 있다. Function Characteristics

fallible 함수는 예외 처리 ( default 값 처리 또는 !를 통한 event 에러 처리 )가 필수이다.
VRL은 잠재적 오류를 처리 하지 않으면 compile하지 않는 fail-safe language라고 한다. VRL error reference
# number가 float가 아닐 경우 에러 로그를 보여주고 event를 제외한다. 다음 event는 정상 처리된다.
.value1 = float!(.number)
# number가 float가 아닐 경우 0.0 값으로 처리한다.
.value1 = float(.number) ?? 0.0
아래에서 사용한 encode_json 함수는 infallible이며 pure함수이기에 별도의 처리없이 사용할 수 있다.
impure 함수의 경우는 원본 데이터의 영향이 있기 때문에 주의하라는 의미인 것 같다.
sink
Vector - Acknowledgement Guarantees
acknowledgements를 활성화하면 event가 sink 완료된 이후 kafka offset을 commit한다. ( at-least-once 보장 )
acknowledgements를 설정하지 않는 경우, source에서 데이터를 받아간 순간 데이터 처리가 되었다고 판단한다.
ack 설정이 없는 경우 consumer group의 Consumer Lag를 보면 바로바로 숫자가 줄어드는 게 확인되지만
ack가 설정된 그룹은 배치기간까지 Lag가 누적되었다가 한 번에 줄어드는 것을 확인했다. ( 참고: 그룹은 새로 생성 )
ack를 설정하고 디스크 버퍼(dataDir)를 사용했다면, 디스크 버퍼에 들어간 순간 데이터 처리로 판단한다.
디스크에 저장되면 vector가 restart 되더라도 자동으로 디스크에 남아있는 데이터를 읽고 retry가 된다고 한다.
k8s의 경우, 디스크를 유지할 수가 없어서 메모리 버퍼를 사용한다.
JSON 타입 데이터 처리
배포 yaml
inputs에는 sources/transforms 다음에 정의한 이름을 활용한다.
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorPipeline
metadata:
name: kafka-s3-pipeline
namespace: platform
spec:
sources:
kafka_source:
type: "kafka"
bootstrap_servers: "dev-kafka-cluster-kafka-bootstrap.common.svc:9092"
topics: ["vector-test"]
group_id: "vector-consumer-group"
auto_offset_reset: "earliest"
key_field: "message_key"
commit_interval_ms: 5000 # 신뢰성을 위한 설정
decoding:
codec: json
transforms:
format_json:
inputs: ["kafka_source"]
type: remap
source: |
del(.topic)
del(.source_type)
del(.partition)
del(.offset)
del(.headers)
. = encode_json(.)
sinks:
s3_sink:
type: "aws_s3"
inputs: ["format_json"]
bucket: "vector-test"
endpoint: "http://HOST:PORT" # MinIO일 경우, endpoint 지정
region: "ap-northeast-2"
key_prefix: "raw/dt=%Y-%m-%d/dth=%Y-%m-%d-%H/"
acknowledgements:
enabled: true # ACK 활성화
filename_append_uuid: true
filename_time_format: "%s"
compression: "none"
encoding:
codec: "text"
# 버퍼 설정
buffer:
type: "memory"
max_events: 10000
when_full: "block"
# max_size: 524288000 # 500MB - disk 사용 시에만 설정
# 배치 설정
batch:
max_bytes: 5242880 # 5MB - 실제 사용 시 파일 사이즈는 max_bytes / 스레드 수 로 보임
timeout_secs: 60
aggregator와 pipeline이 정상적으로 실행된다면 k9s로 true를 확인할 수 있다. 오류가 나면 오류 메시지도 확인할 수 있다.

MinIO에는 내가 설정한 prefix대로 폴더가 생성되고 파일이 저장된다.
Athena에서 쿼리 가능한 형태로 변경하려면 transform으로 event(.)를 encode_json으로 문자열로 처리하고
codec: “text”로 설정해야 한다.
kafka source에서 메타데이터를 제공하지만 del() 함수로 불필요한 필드는 제외한 모습이다.
{"device_name":"device_a","message_key":"test","one":95,"three":37,"timestamp":"2024-12-28T18:01:02.239Z","two":52}
{"device_name":"device_b","message_key":"test","one":-36,"three":-7,"timestamp":"2024-12-28T18:01:02.239Z","two":49}
{"device_name":"device_c","message_key":"test","one":85,"three":34,"timestamp":"2024-12-28T18:01:02.239Z","two":81}
...
참고 : sink에서 encoding codec: “json”으로 설정하면 array 형태로 저장된다. ( transform 없이 사용해서 모든 필드 포함 )
[
{"device_name":"device_a","headers":{},"message_key":"test","offset":62643,"one":-10,"partition":1,
"source_type":"kafka","three":42,"timestamp":"2024-12-28T17:39:19.098Z","topic":"vector-test","two":-48},
...
]
protobuf 타입 데이터 처리
protobuf 타입의 경우에는 decoding 설정과 이미지가 빌드가 필요하다.
message_type은 “package.Message” 형태로 설정한다.
descriptor 파일을 사용하기 위해 COPY 명령어만 추가해서 이미지를 새로 빌드해서 사용하였다. ( aggregator 이미지를 변경 )
참고: aggregator에 configmap을 활용해서 처리해보려 했으나 파이프라인 생성 시 일회성 POD이 실행되는데
이 때 desc_file 유무를 체크해서 오류가 났다.
decoding:
codec: protobuf
protobuf:
desc_file: /protobuf/detection.desc # 컴파일된 proto descriptor 파일
message_type: package.SampleRequest # proto에 정의된 메시지 타입
정리
로컬 환경으로 구성해서 테스트해 본 결과 10,000TPS 트래픽을 처리하더라도 리소스를 많이 사용하지 않고 지연도 크게 없었다.
새로운 프로젝트에 적용했으며, 당장은 실시간으로 처리할 필요가 없고 트래픽도 많지 않아 본격적인 성능 테스트는 아직 진행하지 않았다.
하나의 파이프라인에서 여러 개의 source와 sink를 적용할 수 있다. 주기가 느린 데이터의 경우에는 하나의 파이프라인에 추가로 적용해도
무리가 없을 것으로 보인다.
현재 설정은 namespace 단위로 적용하고 있는데 extra_label_selector로 POD 레이블을 추가해서 특정 레이블을 가진 파드에만 적용할 수 있어 보인다.
실제 firehose를 사용할 때 필요한 비용없이 데이터가 S3에 잘 저장되고 Athena 쿼리도 잘 동작한다.
추후 Vector 활용도가 높아지면 더 자세한 내용을 다룰 예정이다.
References :