Airflow의 AthenaOperator 활용하기
Airflow의 AthenaOperator를 활용하는 방법을 간단하게 정리한다.
airflow 2.10.5 버전을 기준으로 작성되었다.
기본 설명
task_execute_athena_query = AthenaOperator(
task_id = 'execute_athena_query',
aws_conn_id = 'prod_aws_conn',
query = "SELECT ... FROM ...",
output_location = 's3://.../athena_query_result/',
database = '',
workgroup = '',
sleep_time = 10,
)
aws_conn_id는 Airflow에서 AWS 연결 정보를 정의한 connection id를 의미한다.
sleep_time을 활용하면 설정한 주기마다 상태를 확인하며 쿼리가 완료될 때까지 기다린다.
( 람다에서 boto3로 쿼리를 실행할 때는 while문으로 sleep 시간을 주고 쿼리 결과를 확인하는 코드를 작성했었다. )
아테나 Iceberg 테이블에 대한 MERGE 쿼리같은 경우, AthenaOperator로 간단하게 구현할 수 있다.
DAG 실행 후 task의 LOGS 탭을 확인해보면 실제 실행된 쿼리도 확인할 수 있다.
[2025-05-19, 01:10:37 KST] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2025-05-19, 01:10:38 KST] {athena.py:121} INFO - Running Query with params:
QueryString:
SELECT ...
FROM ...
QueryExecutionContext: {'Database': '', 'Catalog': ''}
ResultConfiguration: {'OutputLocation': 's3://.../athena_query_result/'}
WorkGroup:
[2025-05-19, 01:10:38 KST] {base.py:84} INFO - Retrieving connection 'prod_aws_conn'
[2025-05-19, 01:10:38 KST] {connection_wrapper.py:325} INFO - AWS Connection (conn_id='prod_aws_conn', conn_type='aws')
credentials retrieved from login and password.
[2025-05-19, 01:10:38 KST] {athena.py:124} INFO - Query execution id: 119cc791-...-4a73-b4a1-9f908752dab3
[2025-05-19, 01:10:38 KST] {waiter_with_logging.py:88} INFO - Query execution id: 119cc791-...-4a73-b4a1-9f908752dab3,
Query is still in non-terminal state: QUEUED
[2025-05-19, 01:10:48 KST] {taskinstance.py:341} ▶ Post task execution logs
AthenaOperator는 쿼리 ID를 XCOM으로 전달할 수 있다. 이 ID가 곧 S3에 저장된 실행결과 csv 파일이기에 다음 task에서 이를 활용할 수 있다.
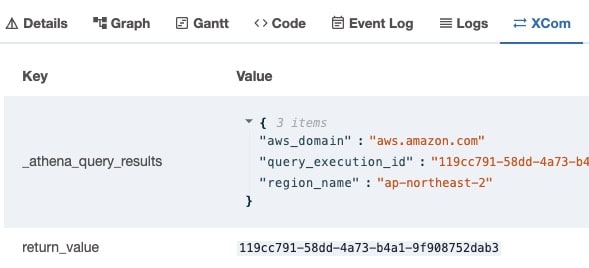
아테나 쿼리 결과 활용
다음의 단계로 활용하였다.
쿼리 생성(PythonOperator) -> 아테나 쿼리 실행(AthenaOperator) -> 쿼리 결과 활용(KubernetesPodOperator)
1 - 쿼리 생성(PythonOperator)
{{ data_interval_start }}와 같은 Jinja template을 활용하면 쿼리문을 DAG 실행 시간에 맞게 작성할 수 있다.
그러나 AthenaOperator 내 쿼리문에 코드 작성이 안 되기 때문에 동적으로 쿼리문을 작성해야 하는 경우,
PythonOperator를 활용할 수 있다. ( ChatGPT 추천 )
PythonOperator에서 provide_context = True로 설정하면 context를 통해 DAG 정보를 받아올 수 있다.
context[‘data_interval_start’]를 활용하면 DAG 시작 정보를 받아 처리할 수 있다.
( 단점은 쿼리 생성도 하나의 task이기 때문에 스케줄러 처리 시간인 20초 정도의 시간이 소요된다. )
2 - 아테나 쿼리 실행(AthenaOperator)
task_execute_athena_query에서 task_make_athena_run_query의 쿼리문을 XCOM으로 받아온다.
query = “{{ ti.xcom_pull(task_ids=’make_athena_run_query’) }}”
3 - 쿼리 결과 활용(KubernetesPodOperator)
task_kubernetes_job에서 task_execute_athena_query의 쿼리 ID를 XCOM으로 받아온다.
arguments=[’–query_execution_id’, ‘{{ ti.xcom_pull(task_ids=”execute_athena_query”) }}’]
이 부분에서 쿼리 ID를 argument로 전달하여 S3에 저장된 쿼리 결과 CSV 파일을 읽어서 처리할 수 있다.
DAG 예시 코드
from airflow import DAG
from airflow.providers.amazon.aws.operators.athena import AthenaOperator
from airflow.operators.python import PythonOperator
from airflow.providers.kubernetes.operators.kubernetes_pod import KubernetesPodOperator
def make_athena_run_query(**context) -> str:
TARGET_TIME_UTC = context['data_interval_start']
TARGET_TIME_KST = TARGET_TIME_UTC.in_timezone('Asia/Seoul')
TARGET_DT_KST = TARGET_TIME_KST.strftime('%Y-%m-%d')
return f"""
SELECT ... FROM ... WHERE dt = '{TARGET_DT_KST}'
"""
#######
# DAG 정의
#######
DEFAULT_ARGS = {
'owner': 'yahwang',
}
DAG_NAME = 'test_airflow_athenaoperator'
BUCKET_NAME = 'BUCKET'
OUTPUT_LOCATION = f's3://{BUCKET_NAME}/athena_query_result/'
with DAG(
DAG_NAME,
default_args=DEFAULT_ARGS,
start_date=pendulum.datetime(2025, 1, 1, tz='Asia/Seoul'),
schedule_interval='@daily',
catchup=False,
max_active_runs=1,
tags=['athena']
) as dag:
task_make_athena_run_query = PythonOperator(
task_id = 'make_athena_run_query',
python_callable = make_athena_run_query,
provide_context = True,
)
task_execute_athena_query = AthenaOperator(
task_id = 'execute_athena_query',
aws_conn_id = 'prod_aws_conn',
query = "{{ ti.xcom_pull(task_ids='make_athena_run_query') }}",
output_location = OUTPUT_LOCATION,
database = '',
workgroup = '',
sleep_time = 10,
)
task_kubernetes_job = KubernetesPodOperator(
task_id='kubernetes_job',
name='kubernetes_job',
namespace='...',
image='...',
cmds=['python', '/app/tasks/kubernetes_job.py'],
arguments=['--query_execution_id', '{{ ti.xcom_pull(task_ids="execute_athena_query") }}'],
...
)
task_make_athena_run_query >> task_execute_athena_query >> task_kubernetes_job
쿼리 실행이 길어진다면 AthenaSensor 활용을 고려할 만하다. 불편한 점이라 하면 PythonOperator 같은 다른 Operator를
통해 쿼리를 실행하고 XCOM을 통해 쿼리 ID를 전달받아야 하는 것으로 보인다.
References :