Apache Sedona로 Spark에서 geospatial 데이터 처리하기
Apache Sedona를 활용하여 Spark에서 geospatial 데이터를 처리하는 방법을 간단하게 정리한다.
개요
기존에는 Athena와 DuckDB를 통해 geospatial 데이터를 처리했으나, 데이터 양이 급증하면서 성능과 비용에 문제가 발생했다.
Spark를 활용해 문제를 해결해보려 했고, Apache Sedona를 사용하면 geospatial 데이터를 처리할 수 있다는 것을 알게 되었다.
Apache Sedona는 Apache Sedona는 대규모 공간 데이터를 처리하기 위한 클러스터 컴퓨팅 시스템이라고 한다.
( a cluster computing system for processing large-scale spatial data )
대표적으로 Spark와 Flink에서 사용할 수 있으며, 메모리 사용량이 적고 성능이 뛰어나다고 한다.
자세한 정보는 아래에서 확인할 수 있다.
Sedona 설치
환경
이미지 : quay.io/jupyter/pyspark-notebook:spark-3.5.3
spark.jars.packages : 추후 spark 버전에 따라 버전 변경이 필요하다.
org.apache.hadoop:hadoop-aws:3.3.4 # S3 접근 용도
org.apache.sedona:sedona-spark-shaded-3.5_2.12:1.7.1 # Sedona ( 주요 종속 라이브러리 포함 )
org.datasyslab:geotools-wrapper:1.7.1-28.5 # Sedona ( Sedona에서 요구 )
https://mvnrepository.com/artifact/org.apache.sedona/sedona-spark-shaded-3.5
https://mvnrepository.com/artifact/org.datasyslab/geotools-wrapper
pip install 명령어로 간단하게 설치할 수 있다. (geopandas는 Sedona에서 설치를 요구한다.)
pip install apache-sedona geopandas
Sedona 기본 사용
from sedona.spark import SedonaContext
config = (
SedonaContext.builder().appName("SedonaTest") \
.config("spark.master", "local[*]") \
.config("spark.driver.memory", "1g") \
.config("spark.executor.instances", "1") \
.config("spark.executor.memory", "2g") \
.config("spark.default.parallelism", "8") \
.config("spark.jars.packages",
"org.apache.sedona:sedona-spark-shaded-3.5_2.12:1.7.1,"
"org.datasyslab:geotools-wrapper:1.7.1-28.5",
) \
.getOrCreate()
)
sedona = SedonaContext.create(config)
.ivy2/jars에 다운로드된 것을 확인할 수 있다.

SQL로도 간단하게 사용할 수 있다.
from pyspark.sql import Row
raw_data = [
Row(id=1, lon=127.0193, lat=37.5156),
Row(id=2, lon=127.0192, lat=37.5158)
]
df = spark.createDataFrame(raw_data)
df.createOrReplaceTempView("raw_points")
points = spark.sql("""
SELECT ST_Point(lon, lat) AS geom
FROM raw_points
""")
points.show(truncate=False)
+------------------------+
|POINT (127.0193 37.5156)|
|POINT (127.0192 37.5158)|
+------------------------+
ST_GeomFromGeoJSON과 ST_GeomFromText를 사용하면 GeoJSON 및 WKT 문자열을 처리할 수 있다.
polygons = spark.sql("""
SELECT ST_GeomFromGeoJSON('{"type": "Polygon", "coordinates": [[[127.00769, 37.56455], [127.00723, 37.56356],
[127.00659, 37.5647], [127.00769, 37.56455]]]}'
) AS geom
""")
polygons = spark.sql("""
SELECT ST_GeomFromText('POLYGON ((127.00769 37.56455, 127.00723 37.56356, 127.00659 37.5647, 127.00769 37.56455))') AS geom
""")
polygons.show(truncate=False)
+-----------------------------------------------------------------------------------------+
|POLYGON ((127.00769 37.56455, 127.00723 37.56356, 127.00659 37.5647, 127.00769 37.56455))|
+-----------------------------------------------------------------------------------------+
Spatial Join 활용
ST_Intersects
테스트 환경 : raw_data 300만 건, target 200건 / CPU 코어 5개, 메모리 2GB 사용량 기준
(DuckDB의 리소스 사용량을 확인한 후, Sedona는 Spark 설정을 조정해 성능을 비슷하게 맞췄다.)
ST_Intersects의 경우, DuckDB가 Sedona보다 약 4배 빨랐다. (사용한 쿼리는 동일하다.)
SELECT name, SUM( .. )
FROM raw_data, target
WHERE ST_Intersects(
ST_GeomFromGeoJSON(target.polygon),
ST_Point(raw_data.longitude, raw_data.latitude)
)
GROUP BY name
%%timeit -n 10 -r 5 으로 실행한 결과
DuckDB : 536 ms ± 3.84 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
Sedona : 2.18 s ± 84.6 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
참고: coordinates 컬럼을 가진 데이터를 Geom 타입 데이터로 변환하는 UDF
”[[127.00769, 37.56455], [127.00723, 37.56356], [127.00659, 37.5647], [127.00769, 37.56455]]”
def to_geojson_polygon(coords):
geojson = {
"type": "Polygon",
"coordinates": [eval(coords)]
}
return json.dumps(geojson, ensure_ascii=False)
to_geojson_polygon_udf = udf(to_geojson_polygon, StringType())
target_df = target_df
.withColumn(
"polygon",
to_geojson_polygon_udf(col("coords"))
)
ST_DistanceSpheroid
테스트 환경 : raw_data 300만 건, target 100건
여기서는 성능 차이가 확연하게 나타났다. Sedona가 DuckDB보다 약 5배 빨랐다. 아래 그림에서 볼 수 있듯, DuckDB는 Sedona보다 약 3배 더 많은 CPU를 사용했음에도 실행 시간이 더 길었다.
아테나로도 동일한 쿼리를 실행해 보았으나, target 데이터가 훨씬 많아 5분이 넘도록 계산이 완료되지 않았다.
Sedona에서는 몇 초 만에 계산이 완료되는 것을 확인할 수 있었다.
리소스 사양을 낮추고 Spot Instance까지 활용하면 성능과 비용을 크게 절감할 수 있을 것으로 보였다.
# DuckDB
SELECT name, SUM( .. )
FROM raw_data, target
WHERE ST_Distance_spheroid(
ST_Point2D(target.lon, target.lat),
ST_Point2D(raw_data.longitude, raw_data.latitude)
) <= target.radius
GROUP BY name
# Sedona
sedona.sql(f"""
SELECT name, SUM( .. )
FROM raw_data, target
WHERE ST_DistanceSpheroid(
ST_Point(target.lon, target.lat),
ST_Point(raw_data.longitude, raw_data.latitude)
) <= target.radius
GROUP BY name
""")
%%timeit -n 10 -r 5 으로 실행한 결과
DuckDB : 9.86 s ± 59.1 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
Sedona : 1.9 s ± 122 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
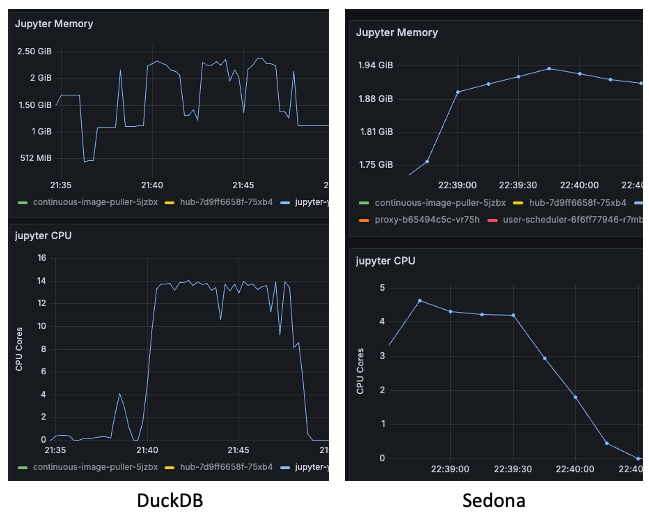
Sedona에서 필요한 기능만 테스트해보았으며, 다양한 기능이 있는 것으로 보인다. 아래 참고 자료에서 더 많은 정보를 확인할 수 있다.
대용량 geospatial 데이터를 처리할 때는 Apache Sedona가 유용해 보인다.
References :