Airflow에서 Spark 배치 작업 실행하기
Airflow에서 Spark 배치 작업을 실행하기 위한 방법을 간단히 정리한다.
spark-operator 설치
kubernetes에서 spark application 배포 및 관리를 위한 spark-operator가 존재한다.
https://github.com/kubeflow/spark-operator
주요 설정 (values.yaml)
spark.jobNamespaces : spark application이 실행될 namespace
아래 주석처럼 모든 네임스페이스를 지정할 수도 있고 특정 네임스페이스를 지정할 수 있다.
특정 네임스페이스를 지정할 경우, 해당 네임스페이스가 이미 존재해야 한다. ( 그렇지 않으면 operator 배포 오류 )
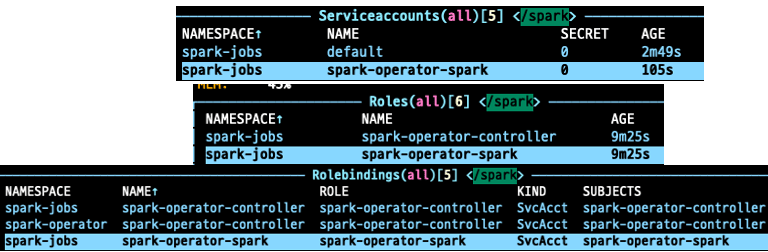
배포되면 spark-operator-spark serviceaccount와 role, rolebinding이 해당 네임스페이스에 생성된다.
추후 배포 시 serviceAccount를 spark-operator-spark로 지정해야 하며,
airflow에서 spark application 배포 시 필요한 권한과도 연관되어 있다.
controller.uiIngress : spark ui 접속 설정
Ingress를 사용하기 위해서는 uiService.enable: true로 설정해야 한다.
urlFormat을 보면 {{$appNamespace}}/{{$appName}} 이런 식으로 설정한 것으로,
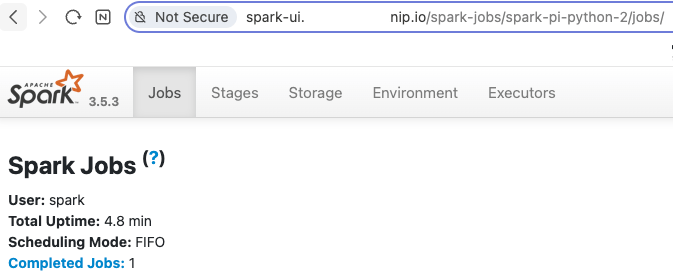
Spark application마다 각각의 UI에 접근할 수 있도록 한 설정이다.
appName은 Spark application의 metadata.name을 의미한다. ( 실제로는 spark-app-name label로 설정된다. )
values-override.yaml
spark:
# If empty string is included, all namespaces will be allowed.
# Make sure the namespaces have already existed.
jobNamespaces:
- default
controller:
uiService:
enable: true
uiIngress:
enable: true
urlFormat: "도메인/{{$appNamespace}}/{{$appName}}"
ingressClassName: "nginx"
prometheus:
podMonitor:
create: true
자세한 설정은 여기서 확인 가능하다. kubeflow/spark-operator
간단한 배포 명령어
helm repo add --force-update spark-operator https://kubeflow.github.io/spark-operator
# values-override.yaml은 변경한 설정 파일
helm upgrade --install spark-operator spark-operator/spark-operator -n spark-operator --create-namespace \
--version 2.1.1 -f ./values-override.yaml
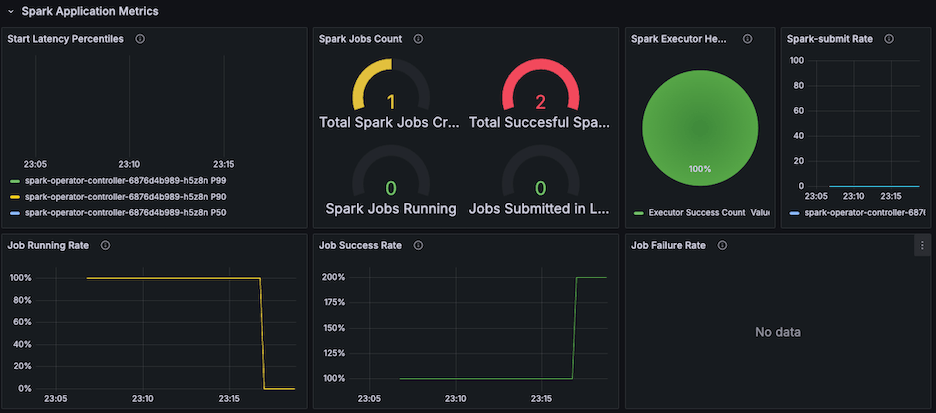
Prometheus가 설치된 경우, PodMonitor를 통해 Operator의 메트릭을 수집할 수 있다. 다음 템플릿을 그대로 사용할 수 있다.
Spark-Operator Scale Test Dashboard - Grafana
실제 메트릭 예시
로컬 배포 테스트
serviceAccount는 spark-operator-spark로 설정해야 한다. ( 미 설정 시 배포 오류 )
참고: 메모리를 너무 낮게 설정하면 배포 오류가 발생하므로 512m 이상이 적정해 보인다.
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi-python
namespace: spark-jobs
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: spark:3.5.3
imagePullPolicy: IfNotPresent
mainApplicationFile: local:///opt/spark/examples/src/main/python/pi.py
sparkVersion: 3.5.3
driver:
cores: 1
memory: 512m
serviceAccount: spark-operator-spark
executor:
instances: 3
cores: 1
memory: 512m
example 코드는 실행 시간이 너무 짧아, 간단하게 다른 코드를 사용해 보았다.
longjob은 Spark python 코드에서 설정한 appName이며, Executor가 3개 생성된 것을 확인할 수 있다.

monitoring 설정
...
spec:
executor:
...
monitoring:
exposeDriverMetrics: true
exposeExecutorMetrics: true
prometheus:
jmxExporterJar: "/opt/spark/jars/jmx_prometheus_javaagent-1.0.1.jar"
port: 8090
portName: jmx-exporter
monitoring은 Spark image에 jmx_prometheus_javaagent를 다운로드 받은 후 Spark application에 설정해야 한다.
Dockerfile 일부
FROM spark:3.5.3
# JMX Prometheus Exporter 1.0.1 버전 다운로드
RUN curl -L -o /opt/spark/jars/jmx_prometheus_javaagent-1.0.1.jar \
https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/1.0.1/jmx_prometheus_javaagent-1.0.1.jar
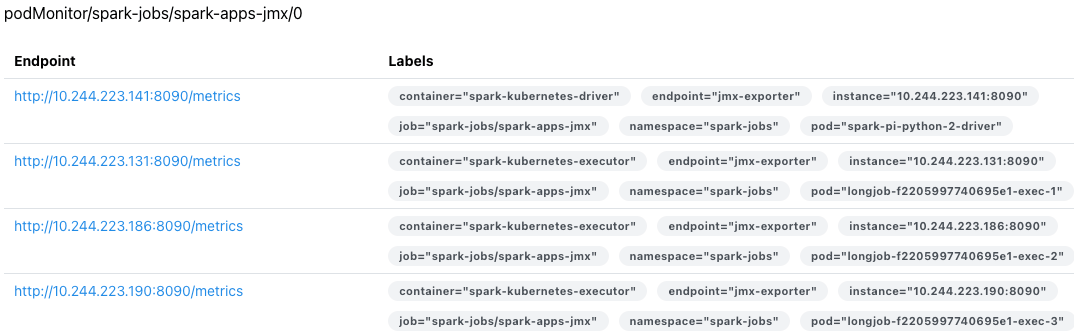
PodMonitor 설정
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: spark-apps-jmx
namespace: spark-jobs
spec:
namespaceSelector:
matchNames:
- spark-jobs
selector:
matchExpressions:
- key: spark-role
operator: In
values:
- driver
- executor
podMetricsEndpoints:
- port: jmx-exporter
path: /metrics
interval: 10s
PodMonitor 확인
airflow Spark DAG
권한 설정
DAG 배포 시 권한 문제로 처음에 다음과 같은 오류 메시지를 확인할 수 있다.
kubernetes.client.exceptions.ApiException: (403) Reason: Forbidden HTTP response headers:
"message":"sparkapplications.sparkoperator.k8s.io is forbidden: User \"system:serviceaccount:common:dev-airflow-worker\"
cannot create resource \"sparkapplications\" in API group \"sparkoperator.k8s.io\" in the namespace \"spark-jobs\"",
"reason":"Forbidden","details":{"group":"sparkoperator.k8s.io","kind":"sparkapplications"},"code":403}
Airflow의 service account를 확인한 후 이미 생성된 spark-operator-controller role binding을 추가하면 된다.
RoleBinding 시에는 Airflow의 namespace와 Spark를 실행할 namespace가 달라도 상관없다.
참고: 네임스페이스가 여러 개일 경우, 각각의 role을 binding해야 한다.
spark-rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: airflow-worker-spark-rolebinding
namespace: spark-jobs
subjects:
- kind: ServiceAccount
name: dev-airflow-worker
namespace: common
roleRef:
kind: Role
name: spark-operator-controller
SparkKubernetesOperator
application_file 또는 template_spec은 둘 중 하나를 선택하여 사용한다.
application_file : Spark application의 yaml 파일
template_spec : Spark application의 spec을 Dict 타입으로 정의한다.
random_name_suffix : Spark application name에 랜덤한 suffix를 추가한다. (Spark UI 접속 시 suffix를 알아야 함)
airflow DAG 정의
...
SparkKubernetesOperator(
task_id='spark_task',
namespace='spark-jobs',
get_logs=True,
application_file='yamls/spark_app_template.yaml',
random_name_suffix=True,
)
자세한 정보는 여기서 확인할 수 있다.
spark_app_template.yaml 예시
참고: driver.labels가 없으면 KeyError 오류가 발생하므로 추가하였다.
XCOM을 통해 이전 task의 결과를 환경변수로 전달해서 사용할 수도 있다.
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication`
metadata:
name: spark-pi-python-2
namespace: spark-jobs
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: harbor도메인/spark/my-spark:0.0.3
imagePullPolicy: IfNotPresent
imagePullSecrets:
- harbor-registry
mainApplicationFile: local:///opt/spark/examples/src/main/python/my_long_job.py
sparkVersion: 3.5.3
sparkConf:
spark.hadoop.fs.s3a.path.style.access: "true"
spark.hadoop.fs.s3a.impl: "org.apache.hadoop.fs.s3a.S3AFileSystem"
spark.hadoop.fs.s3a.aws.credentials.provider: "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider"
spark.hadoop.fs.s3a.endpoint: "s3.ap-northeast-2.amazonaws.com"
spark.hadoop.com.amazonaws.services.s3.enableV4: "true"
driver:
labels:
worker: "airflow"
terminationGracePeriodSeconds: 60
cores: 1
memory: 512m
serviceAccount: spark-operator-spark
env:
- name: APP_NAME
value: "..."
- name: QUERY_EXECUTION_ID_MSP
value: "{{ task_instance.xcom_pull(task_ids='TASK_1') }}"
nodeSelector:
role: dataops
tolerations:
- key: dedicated
operator: Equal
value: dataops
effect: NoSchedule
executor:
terminationGracePeriodSeconds: 60
instances: 3
cores: 1
memory: 512m
nodeSelector:
role: dataops
tolerations:
- key: dedicated
operator: Equal
value: dataops
effect: NoSchedule
monitoring:
exposeDriverMetrics: true
exposeExecutorMetrics: true
prometheus:
jmxExporterJar: "/opt/spark/jars/jmx_prometheus_javaagent-1.0.1.jar"
port: 8090
portName: jmx-exporter
References :