PySpark Structured Streaming 기본 + 모니터링 (with spark-operator)
PySpark Structured Streaming 기본 사용법을 간단하게 정리한다.
spark-operator로 배포하는 SparkApplication(pyspark 3.5.3)을 기준으로 작성되었다.
S3 저장 기본 코드
Kafka에 저장된 JSON 포맷 데이터를 읽어 주기적으로 S3에 저장하는 코드이다. 테스트로는 MinIO를 사용하였다.
spark = SparkSession.builder.appName("StreamingTest") \
.config("spark.jars.packages",
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.3,"
"org.apache.hadoop:hadoop-aws:3.3.4,"
"io.prometheus:prometheus-metrics-core:1.3.8,"
)
.getOrCreate()
custom_schema = StructType([
StructField("message", StringType(), True),
])
kafka_options = {
"kafka.bootstrap.servers": "dev-kafka-cluster-kafka-bootstrap.common.svc:9092",
"subscribe": "pySparkTest",
"startingOffsets": "earliest",
"maxOffsetsPerTrigger": "2000"
}
streaming_df = spark.readStream \
.format("kafka") \
.options(**kafka_options) \
.load() \
.select(
from_json(col("value").cast("string"), custom_schema).alias("json_data"),
col("timestamp").alias("kafka_timestamp")
) \
.select(
col("json_data.*"),
col("kafka_timestamp")
) \
.withColumn("dt", date_format("kafka_timestamp", "yyyy-MM-dd")) \
.withColumn("dth", date_format("kafka_timestamp", "yyyy-MM-dd-HH"))
query = streaming_df.coalesce(3).writeStream \
.format("json") \
.option("path", "s3a://sensor-test/StreamingTest/") \
.option("checkpointLocation", "s3a://sensor-test/StreamingTest_checkpoint/") \
.partitionBy("dt", "dth") \
.trigger(processingTime="2 seconds") \
.outputMode("append") \
.start() \
.awaitTermination()
SparkApplication이 메타데이터와 offset 정보를 관리하기 위해 checkpoint를 생성하지만 S3 저장 파일 경로에는 _spark_metadata 폴더를 생성한다.
checkpoint와 _spark_metadata 폴더의 동기화가 잘 맞아야 한다. checkpoint가 유실되고 _spark_metadata 폴더만 남아 있는 경우,
SparkApplication을 다시 실행해 보면 데이터가 쌓이지 않는다. _spark_metadata 폴더까지 정리하면 다시 처음부터 동작한다.
(App은 실행되었으나, 오류 메시지 없이 배치가 실행되지 않는 현상이 나타났다.)
추가 설정
from_json : JSON 데이터를 구조체로 변환
from_json과 schema를 활용하면 JSON 포맷으로 들어오는 데이터를 쉽게 변환하여 사용할 수 있다.
col(“json_data.*“)처럼 사용하면 {‘value’: {‘message’: ‘test’, ‘id’: 1}}가 {‘message’: ‘test’, ‘id’: 1}로 변환된다.
partitionBy : 파티션
파티션이 될 컬럼을 미리 정의해야 한다. 여기서는 dt=yyyy-MM-dd/dth=yyyy-MM-dd-HH/ 파일 형태로 저장된다.
trigger : 배치 실행 주기
배치 실행 주기이지만, 곧 S3 파일 저장 주기를 의미하기도 한다.
coalesce : coalesce(3)을 지정하였다.
현재 pySparkTest의 파티션은 10개이다. 기본적으로 배치가 끝날 때마다 파티션당 파일 한 개로 저장된다.
파일 저장 개수를 줄이기 위해 coalesce를 사용해 보니, 3개로 통합되어 파일이 저장되는 것을 확인했다.

모니터링
기본 모니터링
SparkApplication yaml에서 monitoring의 configFile과 configuration을 설정할 수 있는데, 아래는 기본으로 설정되는 값이다.
prometheus.yaml - spark-operator
spark.sql.streaming.metricsEnabled를 설정하면, 추가 메트릭을 확인할 수 있다. Spark UI에서 보이는 input Rate 등도 확인할 수 있다.
SparkApplication yaml
...
sparkConf:
spark.sql.streaming.metricsEnabled: "true"
기본 yaml에는 정의되어 있지 않은 듯하여, 모든 메트릭을 확인할 수 있도록 변경해 보니 다음과 같은 metric이 생성된 것을 확인할 수 있었다.
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.eventTime-watermark, type=gauges><>Value"} 0.0
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.inputRate-total, type=gauges><>Value"} 0.0
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.latency, type=gauges><>Value"} 0.0
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.processingRate-total, type=gauges><>Value"} 0.0
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.states-rowsTotal, type=gauges><>Value"} 0.0
metrics<name=spark-jobs.spark-streaming-test.driver.spark.streaming.50acd143-0f37-4e21.states-usedBytes, type=gauges><>Value"} 0.0
이 수치들만으로는 모니터링이 어려워 보여 Consumer lag를 확인하는 방법을 찾아보았다. 아래는 위의 메트릭을 쉽게 정의해서 보기 위한 설정이며, 참고로 남겨둔다.
참고 : Spark UI에서 화면
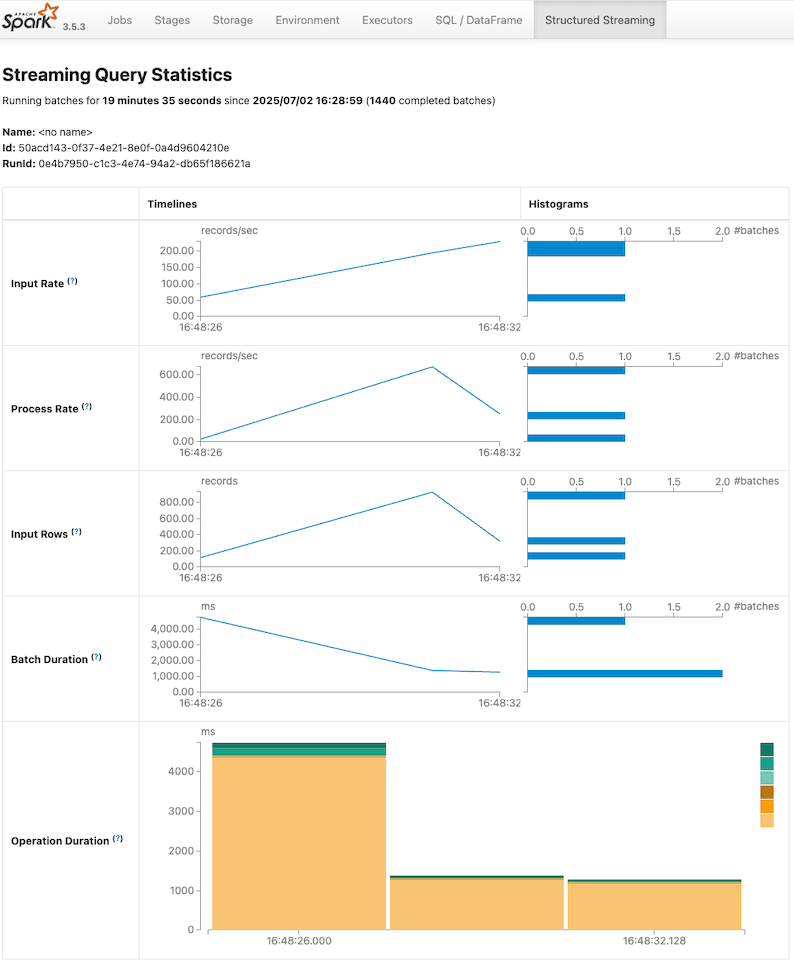
Consumer lag 확인
보통 Consumer Group을 생성해 Consumer LAG 모니터링을 쉽게 할 수 있지만, Spark Streaming은 offset 정보를 파일로 저장한다.
MinIO에 저장된 checkpoint 예시

StreamingQueryListener를 활용하면 offset 정보를 확인할 수 있다. 기본 설명은 StreamingQueryListener - jaceklaskowski.gitbooks.io에서 확인할 수 있다.
event.progress
여기에는 모니터링에 활용할 만한 많은 정보가 담겨 있다. durationMs: 실행 시간 관련, numInputRows: 입력 데이터 수 등…
주목한 건 sources의 metrics이다. 여기에 offset lag 정보가 담겨있다. avg, max, min 각 파티션 lag의 통계치이다.
( durationMs는 상세한 성능 테스트용으로 의미있어 보인다. )
AI 도움을 받아 KafkaOffsetListener를 작성하고 모니터링을 구현했다. 하나의 배치가 실행될 때마다 메트릭이 생성된다.
기존 PodMonitor를 활용해서 metrics를 수집했기에 8091 포트를 추가로 열어서 수집할 수 있게 구성하였다.
SparkSession 설정
prometheus-metrics-core가 필요하다. 그리고 prometheus-client pip 설치가 필요하다.
.config("spark.jars.packages",
...
"io.prometheus:prometheus-metrics-core:1.3.8,"
)
SparkApplication yaml 설정
driver:
...
ports:
- name: metrics
containerPort: 8091
protocol: TCP
PodMonitor 추가 설정
...
podMetricsEndpoints:
- port: jmx-exporter
path: /metrics
interval: 10s
- port: metrics
path: /metrics
interval: 10s
grafana를 통한 모니터링
locust를 통해 트래픽을 발생시켰고 maxOffsetsPerTrigger를 2000으로 설정해, LAG 모니터링이 동작할 수 있는 환경을 구성했다.
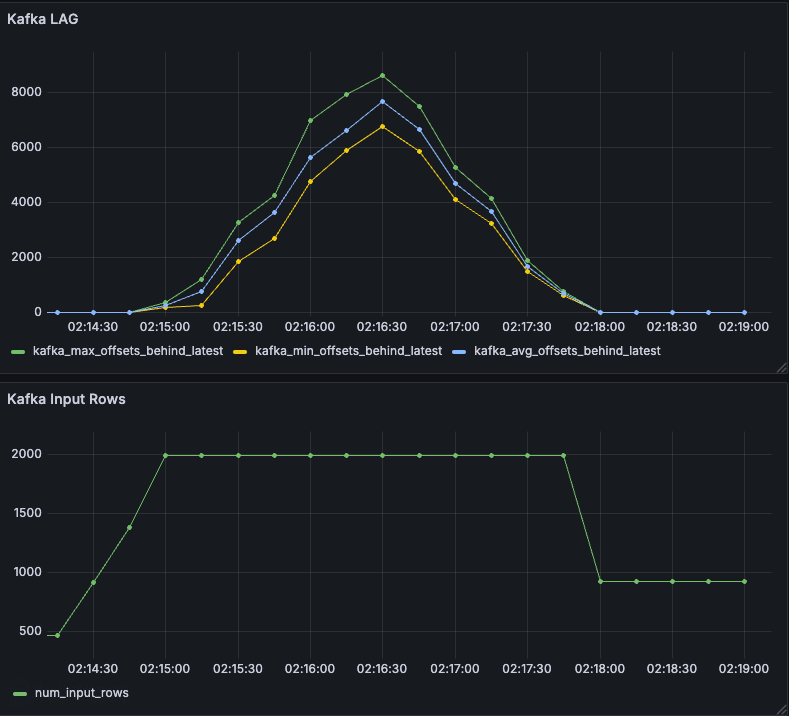
모니터링을 통해 Spark Streaming Application을 잘 활용할 수 있을 것으로 보인다.
사용한 Dockerfile은 https://gist.github.com/yahwang/d31b6d410411f5c5088cbf6e01f3e5fa 여기에서 확인할 수 있다.
PySpark 전체 코드는 https://gist.github.com/yahwang/2b4ad2f66ec2dd5081f48049db00c273 여기에서 확인할 수 있다.
References :