Nessie + Iceberg REST Catalog의 기본 사용법 간단 정리
Nessie + Iceberg REST Catalog의 기본 사용법을 간단히 정리한다. (지속적으로 업데이트 예정)
Iceberg REST Catalog
Iceberg의 내장 카탈로그로는 Hadoop, Hive, REST, Glue, Nessie, JDBC의 6가지가 있다.
Iceberg Catalogs: Choosing the Right One for Your Needs - in Medium 이 글을 한 번 읽어보면 도움이 된다.
REST Catalog는 Iceberg 0.14.0에서 도입되었으며, 하나의 클라이언트로 AWS Glue, Hive, Hadoop 등
어떤 카탈로그 백엔드든 동일한 REST API로 접근할 수 있도록 해준다.
기존에는 각 카탈로그마다 전용 클라이언트와 JAR 파일이 필요했지만, 이제는 표준화된 REST 인터페이스 하나로 모든 백엔드와 통신이 가능해졌다.
Decoupling using the REST Catalog - Apache Iceberg
Nessie
Nessie는 Git과 같은 버전 관리 기능을 제공하는 오픈 소스이다. Nessie 카탈로그가 있지만 REST Catalog 기능도 지원한다.
warehouse는 테이블이 저장될 물리적 스토리지 위치를 추상화한 논리적 개념이며, 하위 폴더에 테이블이 저장된다.
namespace는 테이블들을 그룹화하는 구조로, database와 맵핑이 된다. ( e.g. create database )
테스트를 위해 인증(auth)은 설정하지 않은 상태로 진행하였다.
helm chart values.yaml - yahwang-k8s-manifest 주요 설정
jdbc:
jdbcUrl: jdbc:postgresql://common-postgres-rw.common.svc:5432/nessie?currentSchema=public
# -- The Nessie catalog server configuration.
catalog:
# -- Whether to enable the REST catalog service.
enabled: true
# -- Iceberg catalog settings.
iceberg:
# -- The default warehouse name. Required. This is just a symbolic name;
defaultWarehouse: nessie-warehouse
# -- Iceberg warehouses. Each warehouse is a location where Iceberg tables are stored. Each
# At least one warehouse must be defined.
warehouses:
- name: nessie-warehouse
location: s3://nessie-warehouse/
# -- Catalog storage settings.
storage:
s3:
defaultOptions:
region: ap-northeast-2
endpoint: http://minio.common.svc:80
테스트
기본 DDL
PySpark를 활용하여 테스트를 진행하였다.
Spark Session 생성 코드 템플릿은 pyspark-nessie-iceberg-template - in GitHub Gist에 있다.
# spark.sql(" ... ") 쿼리에 해당하는 부분만 작성
# 네임스페이스 생성
CREATE DATABASE IF NOT EXISTS nessie.analytics
# 테이블 생성
CREATE TABLE IF NOT EXISTS nessie.analytics.ad_report (
campaign_id STRING NOT NULL,
report_date DATE NOT NULL,
impressions BIGINT,
spend DECIMAL(10,2)
)
USING ICEBERG
PARTITIONED BY (
report_date
)
TBLPROPERTIES (
'format-version' = '2',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.metadata.previous-versions-max' = '10',
'history.expire.max-snapshot-age-ms' = '604800000'
);
# 데이터 삽입
INSERT INTO nessie.analytics.ad_report VALUES
('camp_google_001', DATE '2025-01-30', 12500, 185000.00)
SQL 쿼리 실행 시마다 하나의 커밋(commit)이 생성된다.
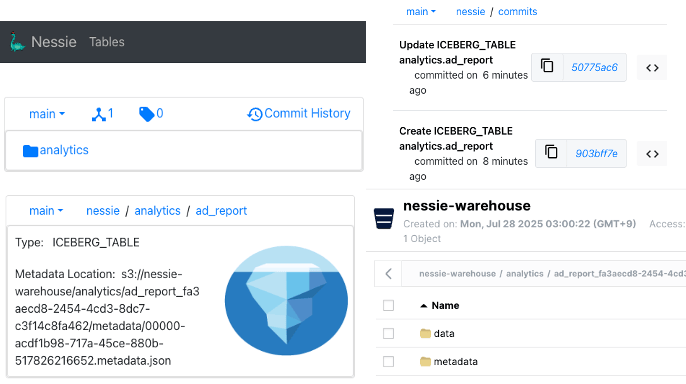
MinIO를 확인해보면 warehouse 폴더 아래에 네임스페이스와 테이블이 생성되어 있다.
Catalog는 최신 메타데이터 파일의 위치를 가리킨다.
다른 서비스와 연동 확인
Datahub와 연동한 화면
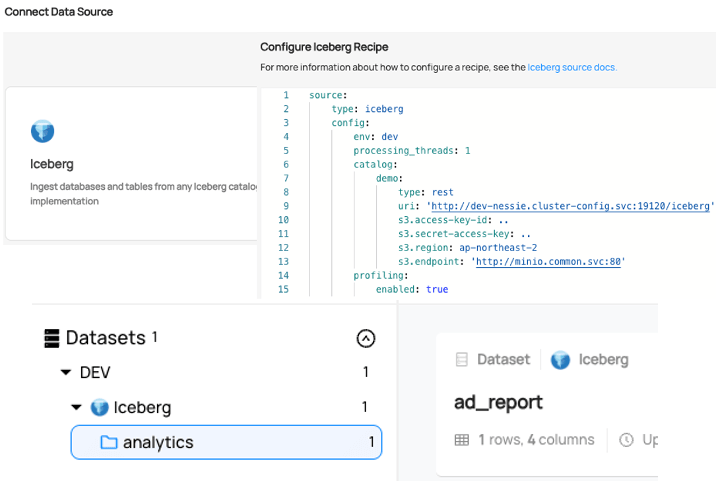
Iceberg REST Catalog + MinIO - in Datahub
Superset에 Trino를 연동한 화면
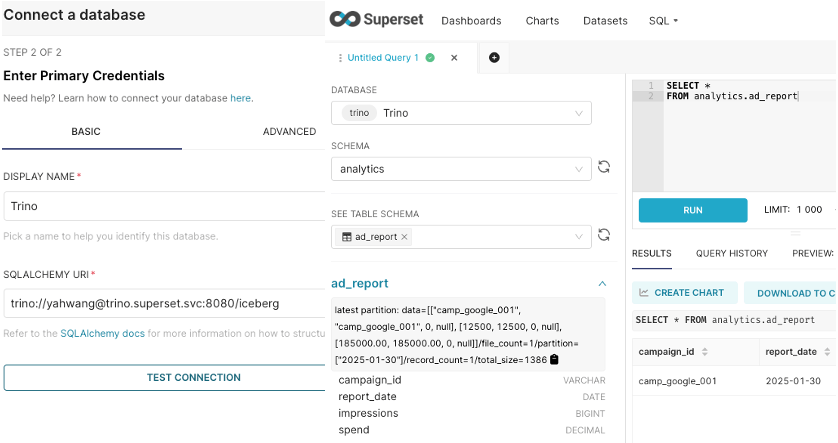
Trino Helm Chart에서 Catalog 설정
catalogs:
iceberg: |
connector.name=iceberg
fs.native-s3.enabled=true
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http\://dev-nessie.cluster-config.svc\:19120/iceberg/
iceberg.rest-catalog.vended-credentials-enabled=true
s3.endpoint=http\://minio.common.svc\:80/
s3.path-style-access=true
s3.region=ap-northeast-2
s3.aws-access-key=...
s3.aws-secret-key=...
BRANCH TEST
특정 브랜치(branch)의 테이블을 사용하려면 테이블@브랜치 형식으로 사용한다.
CREATE BRANCH IF NOT EXISTS add_data IN nessie FROM main
INSERT INTO nessie.analytics.`ad_report@add_data` VALUES
('camp_naver_001', DATE '2025-01-29', 8900, 150000.00);
# main branch
SELECT * FROM nessie.analytics.ad_report
# add_data branch
SELECT * FROM nessie.analytics.`ad_report@add_data`
add_data 브랜치에만 데이터가 추가되었으며, 데이터가 추가된 정보를 가진 메타데이터 파일을 가리킨다.
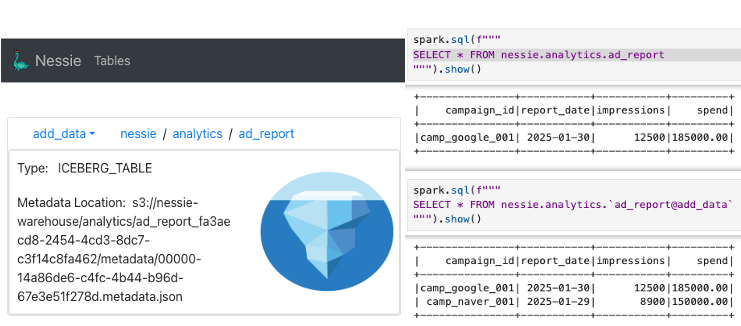
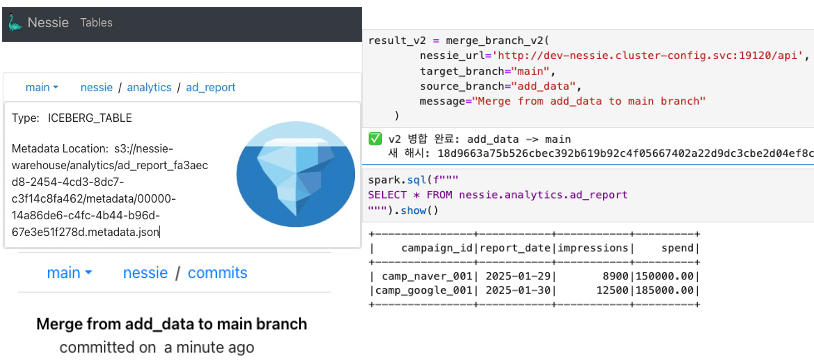
MERGE
브랜치를 생성한 후 데이터를 가공한 뒤, Merge를 하면 main 브랜치에 반영된다.
spark.sql에서는 COMMIT 메시지를 별도로 작성할 수 없다는 문제가 있다.
브랜치에서 작업을 마치고 MERGE할 때, REST API를 활용해 COMMIT 메시지를 작성하는 방법을 시도해보았다.
nessie_merge_branch_v2 - in GitHub Gist 함수는 여기서 확인할 수 있다.
MERGE를 수행하면 main 브랜치의 메타데이터가 add_data 브랜치의 메타데이터와 동일하게 변경된 것을 확인할 수 있다.
Nessie의 기본 사용법을 확인해보았으며, 실제 업무에 연동하여 사용해보고자 한다.
References :