Schema Registry + Avro의 기본 사용법 간단 정리
Schema Registry + Avro의 기본 사용법을 간단히 정리한다. (지속적으로 업데이트 예정)
JSON 대신 Avro를 활용해 보기 위한 테스트이다. Avro VS JSON - itbuddy.log에서 테스트한 결과에 따르면 성능이 2배 더 좋다고 한다.
모든 JSON 방식을 대체할 수는 없겠지만, 데이터 파이프라인에서는 일부 도입할 수 있을 것이라고 생각한다.
참고: Avro 기본 형식
개별 메시지 방식인 Single Object Encoding Format과 파일 방식인 Object Container File Format이 있다.
여기서 다룰 주요한 내용은 매직 바이트(magic bytes)이다. 각 직렬화 방식마다 고유한 매직 바이트가 정의되어 있다.
Wire Format ( 직렬화 방식 )
Single Object Encoding : [C3 01][fingerprint][data]
fingerprint가 key가 되는 JSON 스키마를 별도로 관리해야 한다. Avro JSON Encoding - Single-object encoding
Object Container File : [Obj\x01][header][blocks]
header에 스키마가 포함되어 있다. Avro Object Container File Format
매직 바이트를 확인하면 Reader에서 데이터 해석 방식을 결정할 수 있다.
Schema Registry + Avro
Schema Registry는 다음과 같은 고유한 형식을 따른다.
| Bytes | Area | Description |
|---|---|---|
| 0 | Magic Byte | 매직 바이트이며, 항상 0이다. |
| 1-4 | Schema ID | 4-byte 스키마 ID |
| 5-end | Data | 데이터 |
출처 : Schema Formats for Schema Registry
이 코드를 보면 실제 매직 바이트가 어떻게 동작하는지 확인할 수 있다. from_bytes & id_to_bytes - confluent-kafka-python
Avro Schema
JSON 형태로 구성되며, 아래는 테스트에 사용한 샘플 스키마이다.
{
"type": "record",
"name": "User",
"namespace": "example.avro.sr",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "favorite_number",
"type": [
"int",
"null"
]
},
{
"name": "favorite_color",
"type": [
"string",
"null"
]
}
]
}
구현 테스트
confluent-kafka
스키마 읽는 코드
from confluent_kafka import Consumer, KafkaError
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroDeserializer
from confluent_kafka.serialization import SerializationContext, MessageField
KAFKA_BROKER_URL = 'dev-kafka-cluster-kafka-bootstrap.common.svc:9092'
SCHEMA_REGISTRY_URL = 'http://dev-schema-registry.common.svc:8081'
TOPIC_NAME = 'user-test'
SCHEMA_SUBJECT_NAME = f"{TOPIC_NAME}-value"
consumer_conf = {
'bootstrap.servers': KAFKA_BROKER_URL,
'group.id': 'avro-consumer-group',
'auto.offset.reset': 'earliest'
}
schema_registry_conf = {'url': SCHEMA_REGISTRY_URL}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
latest_schema = schema_registry_client.get_latest_version(SCHEMA_SUBJECT_NAME)
# latest_schema = schema_registry_client.get_version(SCHEMA_SUBJECT_NAME, '1')
# schema_str = latest_schema.schema.schema_str
# 두 번째 인자는 스키마 형식 자리 (None인 경우, 자동으로 스키마를 찾음)
# 세 번째 인자는 역직렬화 후 dict 타입 데이터를 처리하는 부분이다. ( 여기서는 그냥 그대로 반환 )
avro_deserializer = AvroDeserializer(schema_registry_client, None, lambda data, ctx: data)
consumer = Consumer(consumer_conf)
consumer.subscribe([TOPIC_NAME])
try:
while True:
msg = consumer.poll(10.0) # 10초 대기
# 메시지 역직렬화
## SerializationContext : 메시지 역직렬화에 필요한 정보를 담는 객체 ( 토픽 정보 + key or value)
try:
deserialized_value = avro_deserializer(
msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE)
)
print(deserialized_value)
except Exception as e:
print(f"Message deserialization failed: {e}")
except KeyboardInterrupt:
print("\nAborted by user")
finally:
# Clean up
consumer.close()
print("Consumer closed.")
Producer 참고 코드: confluent_kafka_producer_avro_example.py - GitHub Gist
Schema Evolution 확인 Compatibility Level: BACKWARD
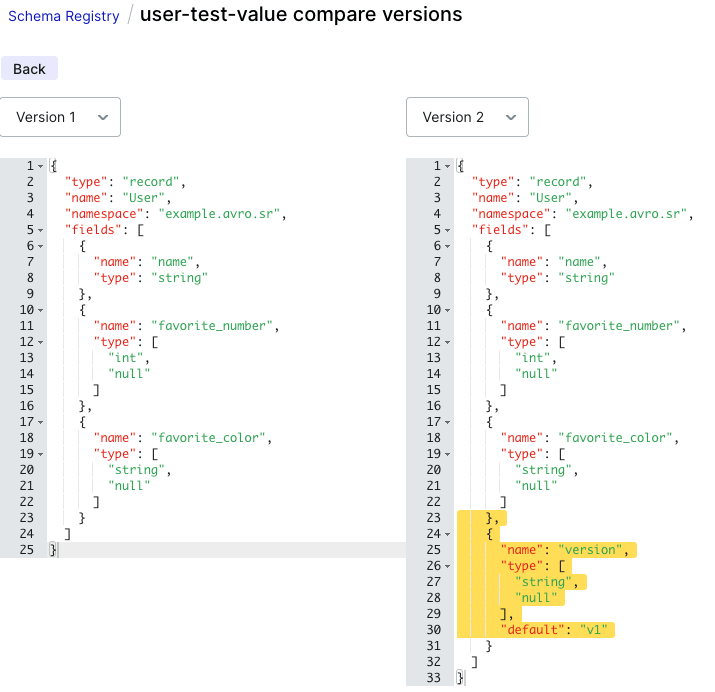
필드 추가 시 Default Value를 지정하지 않으면 에러가 발생한다. Producer에서 스키마 버전 1로 데이터를 보내더라도,
최신 스키마를 읽은 Consumer에서는 version이 default 값인 v1으로 처리된다.
PySpark ( 사용 불편 )
Schema Registry와 Spark를 연동해 주는 ABRiS: Avro Bridge for Spark - GitHub가 존재하지만,
Spark 버전에 맞춰 업데이트되는 속도가 느린 듯하다.
직접 구현하는 방식으로 테스트하면 한계점이 많다.
매직 바이트(1byte)와 스키마 ID(4byte)를 제외한 데이터를 읽는 방식을 사용해야 한다. (아래 Reference 참고)
이렇게 실행할 수는 있지만, Avro Schema 버전이 변경된 후 과거 버전의 데이터가 들어오면 처리하지 못하는 문제가 있다.
# schema_str은 confluent-kafka-python으로 가져온 스키마
from pyspark.sql.avro.functions import from_avro
import pyspark.sql.functions as func
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "dev-kafka-cluster-kafka-bootstrap.common.svc:9092") \
.option("subscribe", "user-test") \
.load() \
.withColumn("fixedValue", func.expr("substring(value, 6, length(value)-5)")) \
.select(
from_avro(col("fixedValue"), schema_str).alias("avro_data")
)
참고: Databricks에서 from_avro 함수를 Schema Registry와 연동하여 바로 사용할 수 있는 기능을 제공하는 듯하다.
Read and write streaming Avro data - Databricks
Kafka Connect
이후…
Flink
이후…
References: