파이썬 크롤링 활용팁 by 엔코아
게시일 : 2018년 01월 16일
# Crawling
# Python
# Requests
# Selenium
엔코아 공감토크에서 진행한 웹페이지 크롤링 강연 노트 –
라이브러리 선택
-
Requests : 파이썬에서 동작하는 작고 빠른 브라우저
- 웹서버로부터 초기 HTML만 받을 뿐, 추가 CSS/JS를 처리하지 않는다.
- 거의 모든 플랫폼에서 구동 가능
- 주로 단순 HTML & Ajax 렌더링 크롤링에 사용
필요한 부분만을 활용할 수 있어서 속도와 효율 면에서 뛰어나다. -
Selenium : 브라우저를 원격 컨트롤하는 테스팅 라이브러리
- 추가 CSS/JS 지원
- 리소스를 많이 잡아먹는다.(실제 브라우저처럼 작동)
- AngularJS, Vue.js, React.JS 류의 자바스크립트 렌더링 크롤링에 사용
Requests로 처리하지 못하는 부분에서 유용하다.
Ajax 렌더링 Requests로 구현
개발자도구 - 네트워크 탭을 활용한다.
성시경을 검색하면 검색결과가 나오면서 index.json이 생성되는 것을 볼 수 있다.
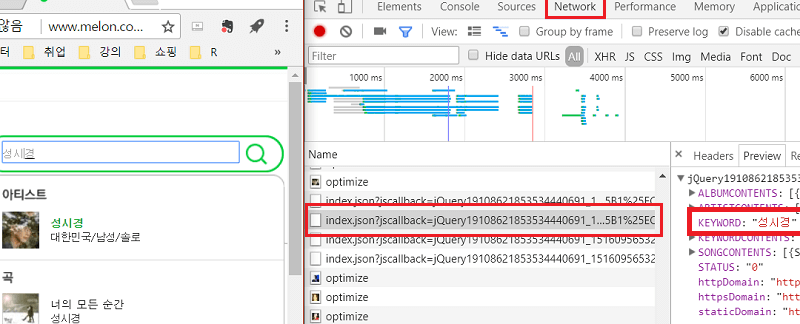
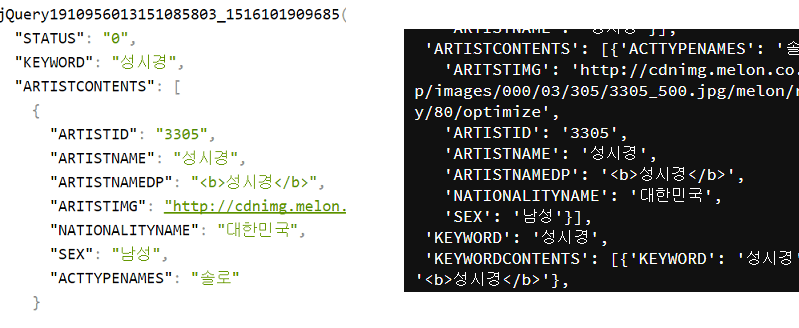
이 json을 활용하여 selenium 대신 requests로 크롤링을 할 수 있다.
Chrome의 JSON VIEWER 확장도구를 사용하여 본 모습(왼쪽) ㅣ Python으로 JSON을 추출한 모습(오른쪽)
import requests
import re
import json
# melon은 user-agent 설정이 필요
headers = {'User-Agent' : '설정값'}
page = requests.get('index.json 주소', headers = headers)
# jquey( json ) 형태에서 json만 정규식으로 추출
# string 형태에서 json(dict)으로 변환
res_str = re.findall('{.+}', page.text)[0]
res_json = json.loads(res_str)
selenium을 사용했다면 모든 웹페이지의 요소를 불러와야 하기 때문에 효율이 매우 떨어진다.
그 외,
- header 설정에 관한 팁(Referer, User-Agent, Accept-Language)
- Django에 크롤링한 데이터를 저장하는 방법(국회의원 명단)
References :