AWS의 Amazon EMR로 Hadoop Cluster 구축하기
Deploying a Hadoop Cluster Lesson 5를 기반으로 작성하였다.
Hadoop Cluster를 AWS의 Amazon EMR로 구축해본다.

출처: https://aws.amazon.com/ko/emr/
Amazon EMR에서는 빅데이터 플랫폼 구축을 위한 EMR release를 제공한다.
기본적으로 계속 유지할 클러스터와 특정 task 수행을 위한 임시적인 클러스터로 나누어서 구성할 수 있다.
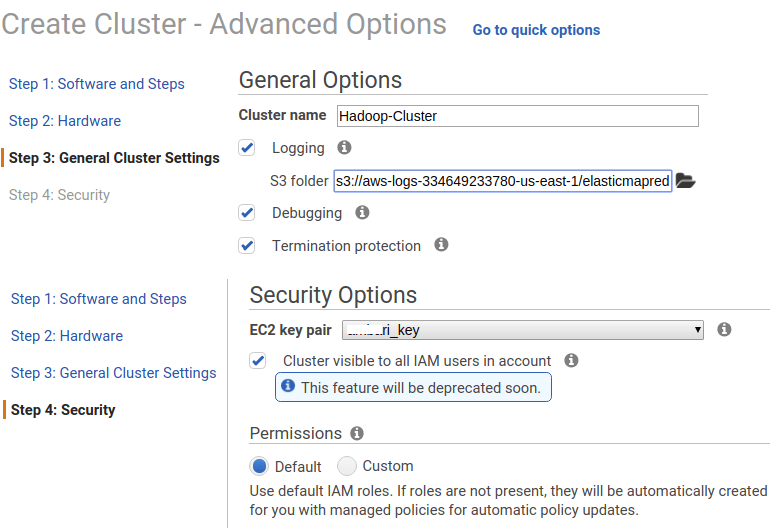
클러스터 구성
Create Cluster에서 Go to advanced options를 클릭 후 원하는 구성을 설정할 수 있다.
Add steps는 클러스터가 임시적인 역할일 때, steps를 정의하고 auto-terminate를 클릭하면 cluster가 task 수행 후 자동으로 종료된다. (step 사용 방법은 아래 쪽에 있음)
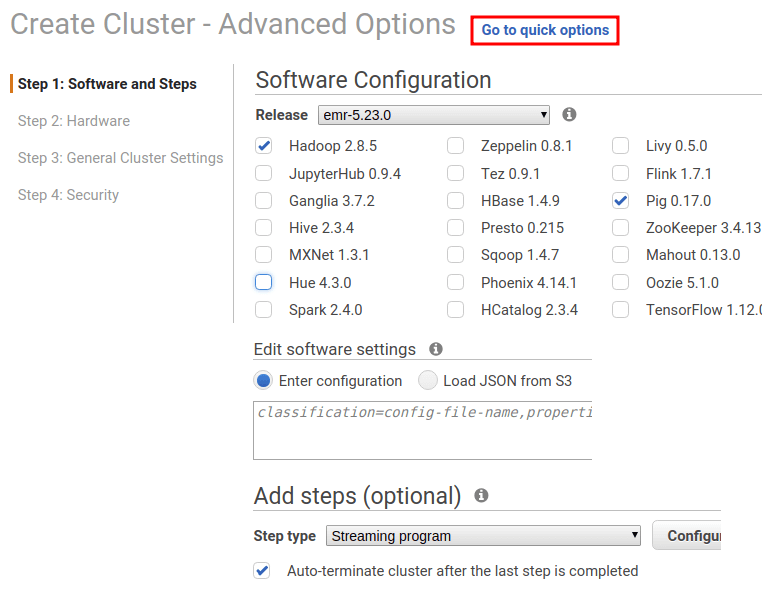
software settings에서는 각 application에 필요한 설정을 JSON 형태로 입력할 수 있다. 참고 : Configuring Applications
그 중, 하둡에 관한 설정은 이 곳에서 확인할 수 있다. Configuring Hadoop
대표적인 설정으로 replication의 개수와 blocksize가 있는데 AWS에서는 node의 개수마다 replication을 설정한다. 4개 이하의 node는 1, 10개 이하는 2, 그 이상은 3을 default로 설정한다. 참고
하둡의 경우, 사용자가 어떤 하드웨어를 선택하는 가에 따라 하둡 default 설정이 존재한다. Configuring Hadoop에서 확인 가능하다.
Node type에서 Core는 데이터를 저장하는 데 초점이 맞춰진 node이고 task는 병렬 처리를 위한 추가 node 개념인 듯 하다.
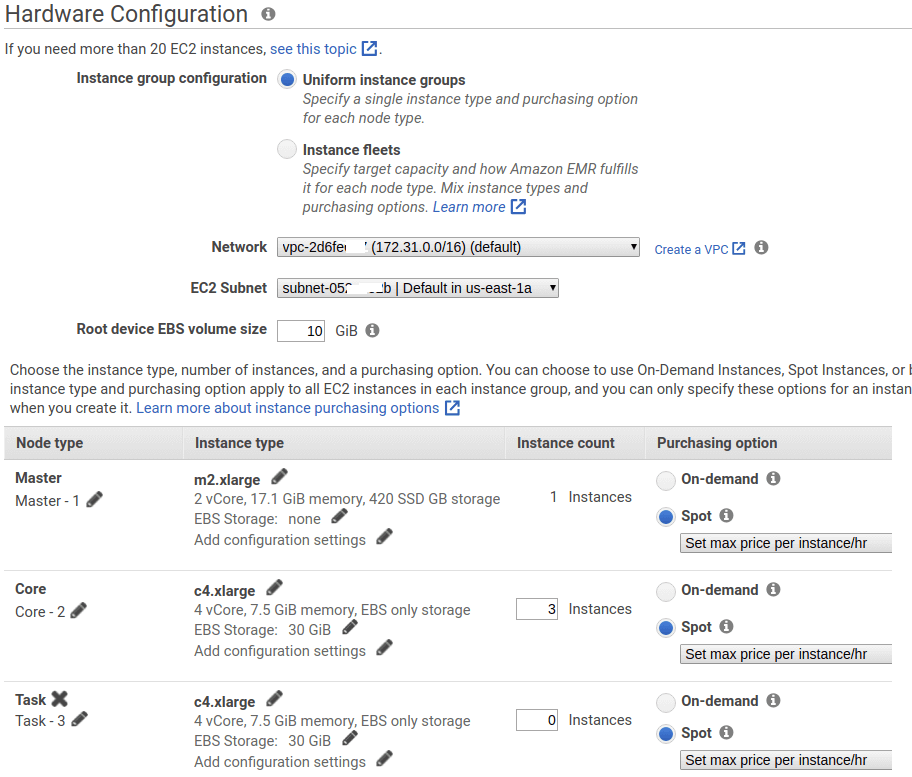
기타 설정을 거치면 클러스터 생성이 시작된다.
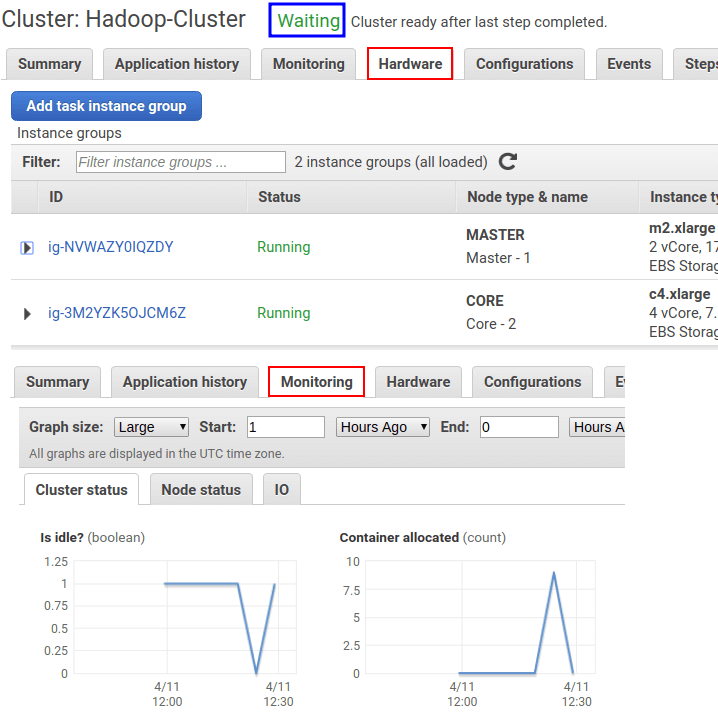
하둡만을 선택하고 클러스터를 생성할 때 약 10분 정도 걸렸다. Cluster가 Waiting 상태가 클러스터 구성이 완료되었다는 의미이다.
여러 클러스터 관리를 위한 기본 서비스를 확인할 수 있다.
MapReduce 실행
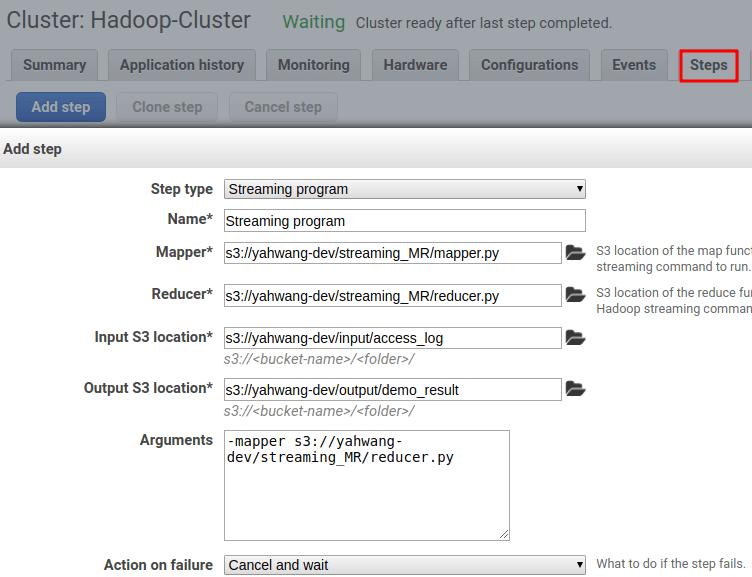
Steps는 클러스터의 JOB을 정의하고 실행할 수 있는 서비스이다. 이 step을 클러스터 구성 처음에 설정하면 JOB을 실행 후 클러스터가 종료되는 것이다.
S3를 통해 MapReduce 사용에 필요한 파일들을 가져와 실행한다. 필수 이외에 필요한 설정은 arguments에 추가로 작성할 수 있다.
테스트는 Deploying a Hadoop Cluster 과정에서 제공하는 예시 mapreduce test files를 가지고 진행했다.
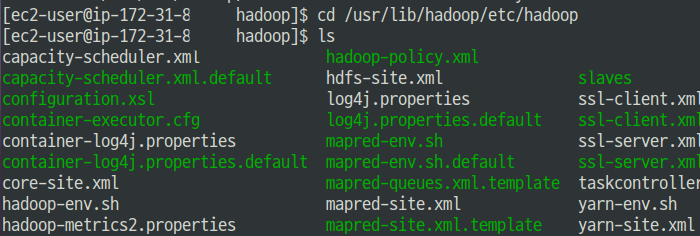
SSH로 master instance를 연결해보면 하둡 설정파일들을 확인하고 수정할 수도 있다.
References :