뉴스 데이터를 활용한 워드클라우드(with BigKinds)
게시일 : 2017년 11월 24일
# R
# wordcloud
BigKinds는 한국언론진흥재단이 운영하는 뉴스빅데이터 분석시스템이다. –
자체 분석서비스도 이용할 수 있지만 데이터를 엑셀파일로 다운받아 활용할 수 있다.
뉴스검색을 통해 최대 2만건의 기사데이터를 xlsx파일로 한 번에 다운로드 받을 수 있다.
파일 안에는 기사 원문의 일부만 포함되어 있지만, 원문에서 추출한 키워드는 제공해준다.
KoNLP를 활용해서 단어 추출을 하지 않아도 되는 점이 매우 유용하다.
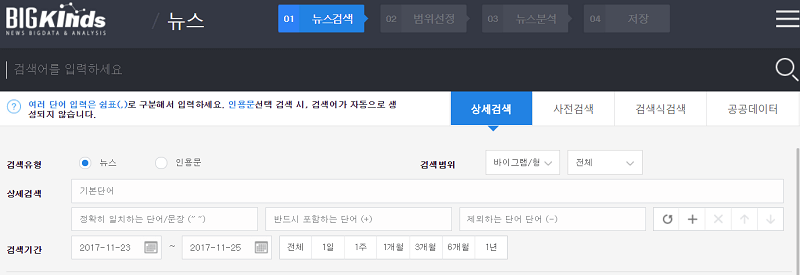
2017년 1월부터 10월까지의 청년실업 관련 2485건의 뉴스 데이터를 사용했다.
데이터 로딩
library(dplyr)
library(stringr)
# 엑셀파일 로딩
news_df <- readxl::read_excel('NewsResult.xlsx',sheet = 1)
# 데이터 프레임을 벡터로 변환한다.
news_vec <- news_df %>% select('키워드') %>% unlist(use.names = F)
데이터 가공
한 기사의 키워드 셀은 하나의 character로 존재하기 때문에 , 단위로 분리해주어야 한다.
{키워드1,키워드2,키워드3,...}
# 키워드를 담을 list 생성
keywords <- vector('list', length=length(news_vec))
# , 단위 분리 & 중복 단어 제거
for ( i in 1:length(keywords)){
words <- unlist(str_split(news_vec[i],','))
keywords[[i]] <- unique(words)}
# 단어 별 카운트 후 정렬
word_count <- table(unlist(keywords))
word_count <- as_tibble(word_count) %>% rename(word=Var1, freq=n) %>% arrange(desc(freq))
# 불필요한 단어 정리( 청년실업은 검색어 )
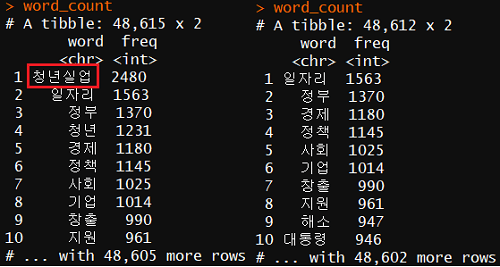
rm_cond <- !(word_count$word %in% c('청년실업','청년','실업'))
word_count <- word_count[rm_cond,]
2485건의 기사에서 중복 제외 398448개의 단어를 추출하고 정리했다.
워드 클라우드 만들기 with wordcloud2
library(wordcloud2)
top_50 <- word_count[1:50,]
wordcloud2(top_50, size=0.5, color='random-light', backgroundColor = 'black')
# 지도 이미지 워드 클라우드
wordcloud2(top_50, size=0.5, color='random-light', backgroundColor = 'black', figPath = 'korea.png')

Link :