Python의 Thread 사용에 대한 이해
Python에서 Thread에 대해 알아본다.
An Intro to Threading in Python을 기반으로 작성하였다.
Thread
Thread는 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. (a separate flow of execution)
파이썬에서 Multi-Threading은 GIL때문에 I/O bound Program에 사용하기 적합하다.
Python에서는 기본으로 threading이라는 라이브러리를 활용할 수 있다.
import threading
def add(res, num):
print("start add func")
for i in range(num):
res +=i
print("end add func")
# target : 실행할 함수
thread = threading.Thread( target=add, args=(0,1000) )
thread.start() # 스레드 시작
start add func
end add func
args : tuple 타입 ( parameter가 1개라면 (,) 형태를 사용해야 한다. )
Non-daemon VS Daemon Threads
Non-daemon Threads
메인 스레드의 모든 코드를 수행하더라도 모든 스레드의 작업이 끝나야 프로그램이 종료된다. (대기 시간이 생김)
import logging
import threading
import time
logging.getLogger().setLevel(logging.INFO)
def thread_function(name):
logging.info(f'Thread {name}: starting')
time.sleep(2)
logging.info(f'Thread {name}: finishing')
logging.info("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
logging.info("Main : before running thread")
x.start()
logging.info("Main : wait for the thread to finish")
logging.info("Main : all done. Waiting non-daemon threads to finish")
INFO:root:Main : before creating thread
INFO:root:Main : before running thread
INFO:root:Thread 1: starting
INFO:root:Main : wait for the thread to finish
INFO:root:Main : all done. Waiting non-daemon threads to finish
INFO:root:Thread 1: finishing
Daemon Threads
데몬 스레드는 백그라운드에서 실행되는 스레드이다.(a process that runs in the background)
프로그램이 종료될 때 데몬 스레드도 함께 종료되는 특징을 가지고 있다.
# Thread 생성 시 daemon=True를 입력한다.
logging.info("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,), daemon=True)
logging.info("Main : before running thread")
x.start()
logging.info("Main : wait for the thread to finish")
logging.info("Main : all done. Exit the program and kill daemon threads")
INFO:root:Main : before creating thread
INFO:root:Main : before running thread
INFO:root:Thread 1: starting
INFO:root:Main : wait for the thread to finish
INFO:root:Main : all done. Exit the program and kill daemon threads
INFO:root:Thread 1: finishing
.join() : main스레드가 다른 스레드 작업이 끝나기를 기다린다.
threads = list()
for index in range(3):
logging.info("Main : create and start thread %d.", index)
x = threading.Thread(target=thread_function, args=(index,))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
thread.join() # 각각의 thread가 끝나기를 기다린다.
logging.info("Main : thread %d done", index)
INFO:root:Main : create and start thread 0.
INFO:root:Thread 0: starting
INFO:root:Main : create and start thread 1.
INFO:root:Thread 1: starting
INFO:root:Main : create and start thread 2.
INFO:root:Thread 2: starting
INFO:root:Thread 0: finishing
INFO:root:Main : thread 0 done
INFO:root:Thread 1: finishing
INFO:root:Main : thread 1 done
INFO:root:Thread 2: finishing
INFO:root:Main : thread 2 done
참고 : 스레드가 실행되는 순서는 운영 체제에 의해 결정되기 때문에 실행순서가 코드와 같음을 보장할 수 없다.
ThreadPoolExecutor - 코드 실행 순서가 곧 Thread 실행순서
ThreadPoolExecutor은 concurrent.futures 라이브러리의 일부이다. (Python 3.2 부터 사용가능)
max_worker : thread의 개수
.map : list와 같은 형태로 args를 전달하면 thread에 하나씩 전달된다. (한 번에 실행)
.submit : thread마다 args를 각각 전달하는 코드 (반복 실행)
import concurrent.futures
import logging
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: # with와 함께 사용을 권장
executor.map(thread_function, [0,1,2]) # 3개
# executor.submit(thread_function, 0) \ executor.submit(thread_function, 1) \ ...
INFO:root:Thread 0: starting
INFO:root:Thread 1: starting
INFO:root:Thread 2: starting
INFO:root:Thread 0: finishing
INFO:root:Thread 1: finishing
INFO:root:Thread 2: finishing
ThreadPoolExecutor 사용 시 주의사항
parameter가 없는 function에 args를 전달하면 아무런 output없이 프로그램이 종료된다.
(excpetion이 발생하는 데 threadpoolexecutor는 이 exception을 숨기기 때문)
Race condition
두 개 이상의 thread가 공유 자원을 사용할 때 잘못된 결과가 발생할 수 있는 상황을 말한다.
예시
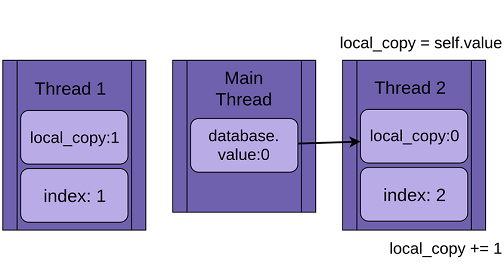
초기값이 0인 DB에 thread 실행 시 하나씩 값을 올리려는 프로그램
각각의 thread는 DB의 값을 변수에 복사 후에 1을 더한 값을 다시 DB에 write한다.
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
import logging
import concurrent.futures
import time
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
for index in range(1,4):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
INFO:root:Testing update. Starting value is 0.
INFO:root:Thread 1: starting update
INFO:root:Thread 2: starting update
INFO:root:Thread 3: starting update
INFO:root:Thread 1: finishing update
INFO:root:Thread 2: finishing update
INFO:root:Thread 3: finishing update
INFO:root:Testing update. Ending value is 1.
Ending value가 3이어야 하는데 race condition으로 인해 1이 되었다.
thread가 CPU를 사용하지 않을 때 context switching이 발생해 다른 thread가 실행된다. 그 시점은 정확히 알 수 없다.
이 특성으로 인해 Thread1이 DB에 1을 write하기 전에 Thread2가 먼저 DB의 0인 값을 가져가버리기 때문이다.
race conditon 해결방법 1 : Lock
공유 자원을 사용중인 스레드가 DB에 value를 write할 때까지 다른 스레드가 접근을 못하게 막을 수 있다.
lock은 acquire & release 함수를 통해 사용할 수 있다.
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock() # lock 생성
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock: # with문 활용(acquire, release 자동 적용)
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
import logging
import concurrent
import time
import threading
if __name__ == "__main__":
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.locked_update, index)
logging.info("Testing update. Ending value is %d.", database.value)
02:23:44: Testing update. Starting value is 0.
02:23:44: Thread 0: starting update
02:23:44: Thread 1: starting update
02:23:44: Thread 0 about to lock
02:23:44: Thread 1 about to lock
02:23:44: Thread 0 has lock
02:23:45: Thread 0 about to release lock
02:23:45: Thread 0 after release
02:23:45: Thread 1 has lock
02:23:45: Thread 0: finishing update
02:23:45: Thread 1 about to release lock
02:23:45: Thread 1 after release
02:23:45: Thread 1: finishing update
02:23:45: Testing update. Ending value is 2.
Lock의 문제점
- Deadlock - Lock이 release 되지 않아 다른 스레드가 lock을 얻지 못해 무한 대기하는 경우를 주로 말한다.
- lock 사용이 많아질 경우 acquire & release 과정에서 overhead가 발생
참고 : RLock은 lock이 release되지 않아도 acquire을 호출할 수 있는 object이다. R : reentrant (다시 들어간다는 뜻)
race conditon 해결방법 2 : Queue를 활용한 예제 ( Queue는 thread-safe하다. )
참고 : producer-consumer-using-queue