Pandas를 Numpy로! 최적화 시리즈(1) - ndarray 활용
Numpy의 ndarray만 활용해도 성능을 높일 수 있다.
글 하단에 내용과 관련된 코드 실행결과가 담긴 Colab 노트북 파일을 확인할 수 있다.
참고 : 데이터 타입 관련
pandas는 기본 설정으로 가장 큰 데이터 타입을 사용하기 때문에 메모리가 낭비된다.
타입만 잘 조절해도 메모리를 절약하고 성능을 높일 수 있다. 아래 영상에서 친절한 설명을 들을 수 있다.
Youtube 영상 : 뚱뚱하고 굼뜬 판다스(Pandas)를 위한 효과적인 다이어트 전략 - by 오성우 (PyCon 2019)
pandas & numpy
pandas는 numpy 기반으로 구성되어 있다. 따라서, pandas의 Dataframe, Series 그리고 Numpy의 ndarray는 메모리를 공유한다.
pandas는 데이터프레임의 한 컬럼을 Series라는 타입으로 다룬다. .values 또는 to_numpy()를 활용하면 ndarray형태로 변환할 수 있다.
np.shares_memory( df["l_name"], df["l_name"].values )
np.shares_memory( df["l_name"], df["l_name"].to_numpy() )
# True
.values 또는 to_numpy() 활용 + 주의 : .array
우리가 일반적으로 사용하는 코드에 .values만 붙여도 성능이 좋은 코드를 작성할 수 있다.
Series는 python이 관여해서 느린 반면, ndarray는 C extension이 빠르게 처리해준다고 한다.
.values를 사용하면 간편하지만, 문서를 보면 .to_numpy() 사용을 권장한다. 그 이유는 .values가 무조건 ndarray를 return하지 않는다.
특정 type에는 pandas extension array를 return한다. 자세한 설명은 하단에서 다룬다.
numeric 타입의 경우, 메모리 최적화를 하지 않았을 경우에 .values만 사용해도 나은 성능을 보인다.
object 타입의 경우, 성능이 빨라지는 것을 많이 체감할 수 있다.
# 일반 코드
df[ (df["l_name"] == "Smith") & (df["age"] < 30) ]
# .values 활용
df[ (df["l_name"].values == "Smith") & (df["age"].values < 30) ]
참고 :
numpy의 문자열 타입은 unicode이다. .values 실행 시 numpy의 object 타입은 python의 object 개념을 말한다.
numpy의 문자열은 C를 활용해서 처리 방식이 다르기 때문에 object로 처리한다. unicode로 바꿀 경우, 오히려 성능이 떨어진다.
.array - Pandas의 extension array
Pandas에는 extension array라는 특별한 케이스가 존재한다. 특정 타입에는 .values가 .array와 같은 결과를 return한다.
이 링크를 통해 다양한 종류를 확인할 수 있다. 참고 : Pandas Series: array() function - w3resource
category 타입은 대표적인 extension array가 사용되는 예이다. extension array는 메모리를 공유하지 않지만 성능 효과는 볼 수 있다.
.values나 .array를 사용하면 Categorical array를 반환되고, to_numpy()를 사용할 경우, ndarray 형태로 반환된다.
이 때는 .values 또는 .array만 활용해야 한다. to_numpy()는 오히려 속도가 매우 느려진다.
np.shares_memory(df["sex"], df["sex"].values)
# False
type(df["sex"].values), type(df["sex"].to_numpy()), type(df["sex"].array)
# (pandas.core.arrays.categorical.Categorical, numpy.ndarray, pandas.~~~~.Categorical,)
참고 1 : numexpr
numexpr은 numpy array의 단순 연산의 성능을 높여주는 evaluator라고 한다. 연산 뿐 아니라 하나의 논리 기호 사용도 지원한다.
연산을 통해 컬럼을 생성하는 경우, 효과적일 수 있다. 단, 표현식에 ndarray로 선언된 변수를 사용해야 해서 메모리가 낭비될 수 있다.
import numpy as np
import numexpr as ne
# .values
df["credit"].values / 1000 * 3
# numexpr
arr = df["credit"].values
ne.evaluate("arr / 1000 * 3")
참고 2 : eval & query 함수 with numexpr
query는 df.loc[ pd.eval( … ) ]와 결과가 같다.
eval & query는 numpy보다는 성능이 떨어지지만 메모리는 효율적으로 활용할 수 있다고 한다.
다중 조건을 사용하는 경우, 일반적 방법은 각각의 결과를 계산 후 마지막 논리 연산을 수행한다.
반면, eval과 query는 row마다 한 번에 모든 조건을 검사해 메모리를 효율적으로 사용한다고 한다.
조건식이 복잡하거나 데이터가 클수록 효과적이다.
# 일반적
df[ (df["l_name"].values == "Smith") & (df["age"].values < 30) ]
# query
df.query("l_name == 'Smith' & age < 30" )
간단하게 사용방법을 정리한 .ipynb 파일 : ![]()
일반적으로, 10,000 row 이상 데이터에 사용을 추천한다고 한다. 또한, numexpr을 활용하면 성능에 효과적이다.
설치만 하면 pandas가 알아서 활용해서 계산한다. ( numexpr이 없으면 python을 사용하는 방식 )
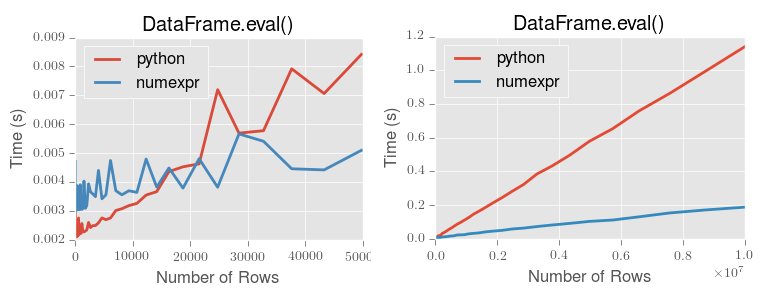
출처 : pandas.eval() performance - pandas docs
모든 내용에 대한 코드 실행해본 노트북 파일
![]()
References :