AWS Data Wrangler(Pandas on AWS) 활용하기
AWS 서비스의 데이터를 Pandas로 활용하는 AWS Data Wrangler에 대해 알아본다.
![]()
참고 : 최신 버전을 설치하는 경우,
MWAA, EMR, Glue PySpark Job 등 Pyarrow 3를 지원하지 않는 곳에 사용하려면
pip install pyarrow==2 awswrangler로 설치한다.
사용 가능한 방법
추가로 boto3에서 제공하는 일부 API 기능도 제공하고 있다. 자세한 내용은 github와 공식문서를 통해 확인가능하다.
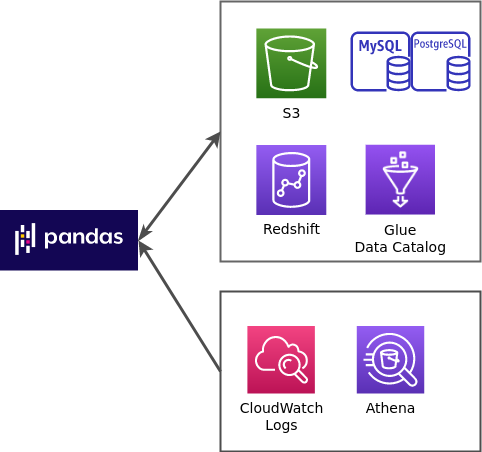
Pandas - S3 활용 예시
1.0 버전부터 boto3 session을 필수로 요구하고 있다.
custom session은 함수마다 지정해야 하며, 그냥 사용할 경우 default user session을 생성해서 처리한다.
import boto3
import awswrangler as wr
session = boto3.Session(profile_name="yahwang")
df = wr.s3.read_csv("s3://.../csvs/tips.csv", boto3_session=session)
# CSV로 저장
## 파일명을 따로 지정해야 하나의 파일로 저장된다.
wr.s3.to_csv(df,path='s3://.../csvs/XXX.csv', header=True, index=False, boto3_session=session)
# parquet로 변환해서 S3에 저장 가능
wr.s3.to_parquet(df, "s3://.../parquets/tips.parquet", index=False, boto3_session=session)
Parquet Datasets
Parquet 타입을 활용할 경우, 컬럼 파티션 기능과 append, overwrite, overwrite_partitions (Partition Upsert) 기능을 제공한다.
AWS Data Wrangler - Parquet Datasets
Lambda layer 제공
github releases에서 Lambda layer를 제공한다. layer 안에는 numpy, pandas, pyarrow 등이 들어있다.
Lambda Layer로 활용 예시
토이 프로젝트를 진행하면서 따릉이 데이터 실시간 API가 대여소 정보를 누락시키거나 새롭게 추가되는 경우가 있었다.
Kinesis Data Analytics에서 S3의 데이터를 reference 테이블 형태로 활용하는 것을 참고해서
데이터 Validation을 Data Wrangler를 활용해서 구현해보았다.
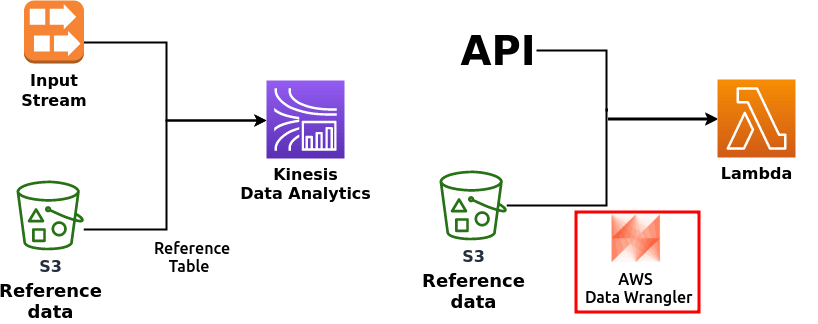
코드의 일부
# rent_api : API로 받은 데이터를 의미
rent_df = pd.DataFrame(rent_api)
st_df = wr.s3.read_csv('s3://.../csvs/st_info.csv')
# indicator 파라미터를 활용한다.
broken = pd.merge(st_df, rent_df, how='outer', left_on='st_id', right_on='stationId', indicator=True) \
.loc[:,['st_id','stationId','_merge']]
| st_id | stationId | _merge | |
|---|---|---|---|
| 0 | ST-1 | nan | left_only |
| 1 | ST-2 | nan | left_only |
| 2 | ST-4 | ST-4 | both |
| 3 | ST-5 | ST-5 | both |
| 4 | ST-6 | ST-6 | both |
| 5 | ST-7 | ST-7 | both |
| 6 | nan | ST-8 | right_only |
데이터를 보면 left_only는 API에서 특정 대여소 정보를 받아오지 못했다는 의미이고,
right_only는 대여소 table의 정보가 없는 새로운 대여소의 데이터를 가져왔다는 것을 확인할 수 있다.
References :