serverless framework를 활용하여 AWS Lambda 배포하기
serverless framework을 활용하여 AWS Lambda를 배포해본다.
AWS에서 Python 기반 Lambda를 배포할 때 Chalice를 활용하는 방법도 있다.
Flask와 유사한 문법을 활용하여 코드가 직관적이고 사용하기가 쉽다고 한다.
Serverless Framework는 다양한 plugin을 통해 복잡한 일을 처리하기에 적합하고 멀티 클라우드를 지원하기 때문에 사용해봤다.
이 글은 친절한 설명보다는 serverless.yml 코드를 분리해서 주요 사용법을 기록하는 용도이다.
여기서는, Serverless Framework와 serverless-python-requirements 플러그인을 사용한다.
실행과정에서 CloudFormation과 S3 bucket이 사용된다.
준비사항
requirements.txt는 각자 사용하는 가상환경(pipenv, poetry, virtualenv 등)에 맞는 커맨드로 생성해준다.
(플러그인이 pipenv와 poetry는 requirements.txt를 자동으로 생성해주는 기능도 제공한다.)
그리고 node.js / npm을 준비한다. node.js와 npm은 플러그인을 설치 및 활용할 때 필요하다.
docker는 serverless-python-requirements의 주요 기능인 Cross compiling 기능을 위해 필요하다.
# serverless framework 설치
(sudo) npm install -g serverless # 전역 설치
# serverless-python-requirements 설치
## 프로젝트 폴더 내에서
npm init (-f)
npm install --save serverless-python-requirements
플러그인 기능 - Cross compiling
Linux가 아닌 MAC이나 WINDOWS 환경에서 설치한 패키지들은 Lambda에서 실행하지 못하는 문제가 있다.
아래 설정을 통해 플러그인이 docker-lambda 이미지를 사용해서 Lambda에서 실행가능한 모듈로 만들어준다.
non-linux로 설정할 경우, linux가 아닌 환경에서만 도커를 사용한다. ( true는 linux도 사용 )
이 설정은 패키지들을 폴더 형태로 제공한다. 용량이 큰 패키지들을 사용하는 경우, Lambda Layer 형태로 사용해야 한다.
custom:
pythonRequirements:
dockerizePip: non-linux
Lambda Layer 활용하기
requirements.txt로 Layer 생성
custom:
pythonRequirements:
dockerizePip: non-linux
# 아래부터 새로 추가
layer:
name: numpy-layer # AWS에서 지정되는 이름
description: Python requirements numpy test layer
compatibleRuntimes:
- python3.6
이미 만들어진 Layer 추가
이미 만들어 놓은 zip파일을 그대로 사용할 수 있다. 여기서는 AWS Wrangler에서 제공하는 파일을 사용했다.
layers:
awswrangler:
package:
artifact: awswrangler.zip
함수에 Layer 적용하기
NAME + LambdaLayer 형태로 활용하며, 첫글자는 대문자로 설정하는 것을 주의해야 한다.
functions:
numpy-func:
handler: handler.main
layers:
- {Ref: PythonRequirementsLambdaLayer} # requirements.txt로 만든 layer
- {Ref: AwswranglerLambdaLayer}
Lambda IAM Role 설정하기
참고로, 여러 함수를 한 번에 배포할 때 함수마다 적절한 Role을 지정하는 용도로 serverless-iam-roles-per-function plugin도 존재한다.
여기서는 지정한 S3 bucket의 데이터를 읽고 수정하는 용도의 기본 role을 지정했다.
provider:
...
iamRoleStatements:
- Effect: "Allow"
Action:
- "s3:ListBucket"
Resource:
- "arn:aws:s3:::${self:custom.BucketName}"
- Effect: "Allow"
Action:
- "s3:getObject"
- "s3:putObject"
Resource:
- "arn:aws:s3:::${self:custom.BucketName}/*"
custom:
BucketName: yahwang-test
serverless.yml 전체 코드
로컬에서만 활용되는 파일들은 package - exclude를 통해 제거해준다.
# serverless.yml
service: numpy-test
plugins:
- serverless-python-requirements
provider:
name: aws
profile: yahwang # AWS profile
region: ap-northeast-2
runtime: python3.6
memorySize: 512
environment: # 보안이 필요한 데이터 (KMS가 적용)
FILE_NAME: ${self:custom.fileName}
iamRoleStatements:
- Effect: "Allow"
Action:
- "s3:ListBucket"
Resource:
- "arn:aws:s3:::${self:custom.BucketName}"
- Effect: "Allow"
Action:
- "s3:getObject"
- "s3:putObject"
Resource:
- "arn:aws:s3:::${self:custom.BucketName}/*"
custom:
fileName: tips
BucketName: yahwang-test
pythonRequirements:
dockerizePip: non-linux
layer:
name: numpy-layer
description: Python requirements numpy test layer
compatibleRuntimes:
- python3.6
package:
exclude:
- node_modules/**
- .venv/**
- package.json
- package-lock.json
- requirements.txt
- awswrangler.zip
layers:
awswrangler:
package:
artifact: awswrangler.zip
functions:
numpy-func:
handler: handler.main
layers:
- {Ref: PythonRequirementsLambdaLayer}
- {Ref: AwswranglerLambdaLayer}
handler.py
# handler.py
import numpy as np
import awswrangler as wr
import os
def main(event, context):
file_name = os.environ["FILE_NAME"] # 환경변수 사용
a = np.arange(15).reshape(3, 5)
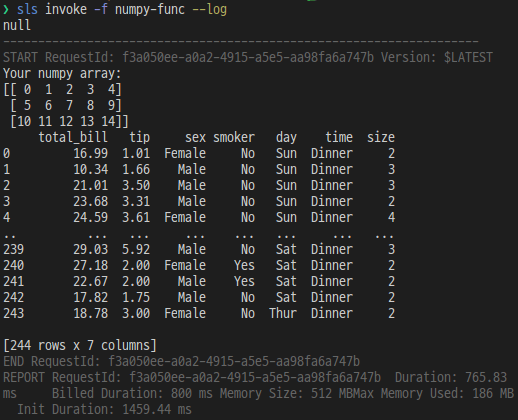
print("Your numpy array:")
print(a)
st_df = wr.s3.read_csv(f"s3://yahwang-test/csvs/{file_name}.csv")
print(st_df)
if __name__ == "__main__":
main("", "")
References :
-
Using Poetry with Serverless Framework to Deploy Python Lambda Functions
-
How to Handle your Python packaging in Lambda with Serverless plugins