AWS Glue 테스트 환경 간단하게 만들기
AWS Glue 테스트 환경을 간단하게 생성하고 활용하는 방법을 알아본다.
Glue는 DynamicFrame이라는 SparkDataFrame보다 더 성능이 좋다고 하는 몇 가지 기능(함수)을 제공하고 있다.
Glue를 활용하고자 한다면 이 기능들을 샘플데이터로 테스트해볼 수 있다.
1. local에서 docker 활용
2달 전부터 AWS에서 docker image를 만들어서 제공해주기 시작했다.
https://hub.docker.com/r/amazon/aws-glue-libs
현재는 glue 1.0버전만 지원하고 있다. jupyter 또는 zeppelin으로 쉽게 활용할 수 있도록 만들어져 편리하다.
glue 라이브러리가 포함되어 있어 glue만의 함수를 사용할 수 있다. 단, 옵션 설정 등은 안 되기도 한다.
-v ~/.aws … 부분은 로컬에 등록된 awscli config와 configure를 그대로 사용할 수 있게 해준다. (단, [default]로 등록되어야 한다.)
# jupyter
docker run -itd -p 8888:8888 -p 4040:4040 -v ~/.aws:/root/.aws:ro --name glue_jupyter \
amazon/aws-glue-libs:glue_libs_1.0.0_image_01 /home/jupyter/jupyter_start.sh
## jupyter lab을 사용하려면 설치 후 url을 tree 대신 lab으로 변경
docker exec -it glue_jupyter pip install jupyterlab
# zeppelin
docker run -itd -p 8080:8080 -p 4040:4040 -v ~/.aws:/root/.aws:ro --name glue_zeppelin \
amazon/aws-glue-libs:glue_libs_1.0.0_image_01 /home/zeppelin/bin/zeppelin.sh
다음과 같은 커널들을 활용할 수 있다. Python3 커널은 PySpark와 더불어 좀 더 커스텀하게 테스트가 가능하다.
basecode (Python3 커널)
from awsglue.context import GlueContext
from pyspark import SparkContext
from pyspark.sql import functions as F
from pyspark.sql.functions import col, pandas_udf, PandasUDFType
from pyspark.sql.types import *
import pandas as pd
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
dynamic_frame = glueContext.create_dynamic_frame_from_options(
connection_type="s3",
connection_options={"paths": ["s3://XXX .csv"]},
format="csv",
format_options={"withHeader": True},
)
2. local jupyter에서 DevEndpoint 활용
실제 규모있는 데이터에서 잘 돌아가는 지 확인하려면 glue를 실제로 돌려보아야 한다. Glue는 DevEndpoint를 생성하고
jupyter 또는 zeppelin을 활용할 수 있도록 하고 있다.
docker image를 통해 어느 정도 기본 로직을 잡은 후 활용하면 비용을 아껴가며 사용할 수 있다.
Glue의 DevEndpoint가 실제 glue 서비스를 돌리는 것과 같기 때문에 비용이 생각보다 많이 나올 수 있다.
DevEndpoint와 연결할 수 있는 notebook을 AWS에서 제공하지만 추가 비용이 또 들고 생성하는 데도 시간이 오래 걸린다.
(알 수 없는 오류에 막히기도 했다.)
DevEndpoint 세팅
먼저, Glue의 DevEndpoint를 생성한다. worker 타입 설정 외에는 모두 default 설정으로 해도 상관없다.
단, SSH 퍼블릭 키를 추가해야 한다.
# ubuntu 버전
ssh-keygen -f ~/.ssh/glue-dev -t rsa -P ""
~/.ssh/glue-dev.pub 내용을 복사 후 붙여넣거나 업로드 한다. Glue 1.0만 지원하기에 10분 정도 기다려야 READY가 된다.

Local 세팅
pip install sparkmagic
# DevEndpoint에서 제공하는 Progress bar 시각화 기능
## jupyter notebook
python -m jupyter nbextension enable --py --sys-prefix widgetsnbextension
## jupyter lab
jupyter labextension install @jupyter-widgets/jupyterlab-manager
pip show sparkmagic
# PySpark 커널 설치
# ...은 Location 위치를 의미
jupyter-kernelspec install [.../site-packages/]sparkmagic/kernels/pysparkkernel --user
Location 정보와 sparkmagic/kernels/pysparkkernel을 합친 후 입력한다.
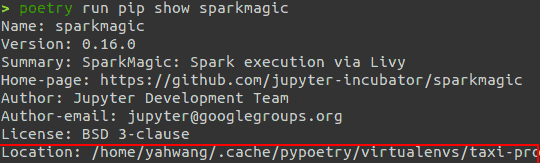
로컬과 연결
공식문서나 AWS Console에서는 이 내용을 알려주지 않는다. Livy server port인 8998을 연결해 주어야 한다.
(169.254.76.1:8998은 아마 공통인 것 같다. 생성한 devendpoint를 클릭해보면 확인 가능)
ssh -i ~/.ssh/id_rsa -vnNT -L 8998:169.254.76.1:8998 glue@ec2–XXXXX.compute-1.amazonaws.com
쉘에서 실행되는 것은 그대로 유지한다. localhost:8998에서 livy UI를 확인할 수 있고 PySpark 커널이 생긴 것을 확인할 수 있다.
# PySpark 커널은 SparkContext가 이미 생성된 경우라 다음과 같이 활용
glueContext = GlueContext(SparkContext.getOrCreate())
References :