Vector aggregator 간단한 성능 확인 ( with k8s )
Vector aggregator를 consumer로 사용했을 때 성능을 간단히 확인해본다.
Vector by datadog 사용기 ( with k8s )에 이어지는 글이다.
테스트 환경
-
같은 클러스터 내 카프카 토픽 ( 파티션 10개 )
-
python client로 IOT 데이터라 가정하고 JSON 데이터 전송 ( 데이터 포맷: 아래 코드 참조 )
-
JSON 데이터를 minIO에 NDJSON(Newline Delimited JSON)방식으로 적재
성능 확인을 위해 Prometheus + Grafana 대시보드를 구축했다.
prometheus-operator를 통해 Prometheus를 구축했고, Aggregator YAML에서 internalMetrics를 활성화했다면
vector-operator가 Podmonitor를 자동으로 생성해서 metric 수집이 바로 가능하다.

수집 가능한 Metric 정보는 아래 링크에서 확인할 수 있다.
테스트 결과
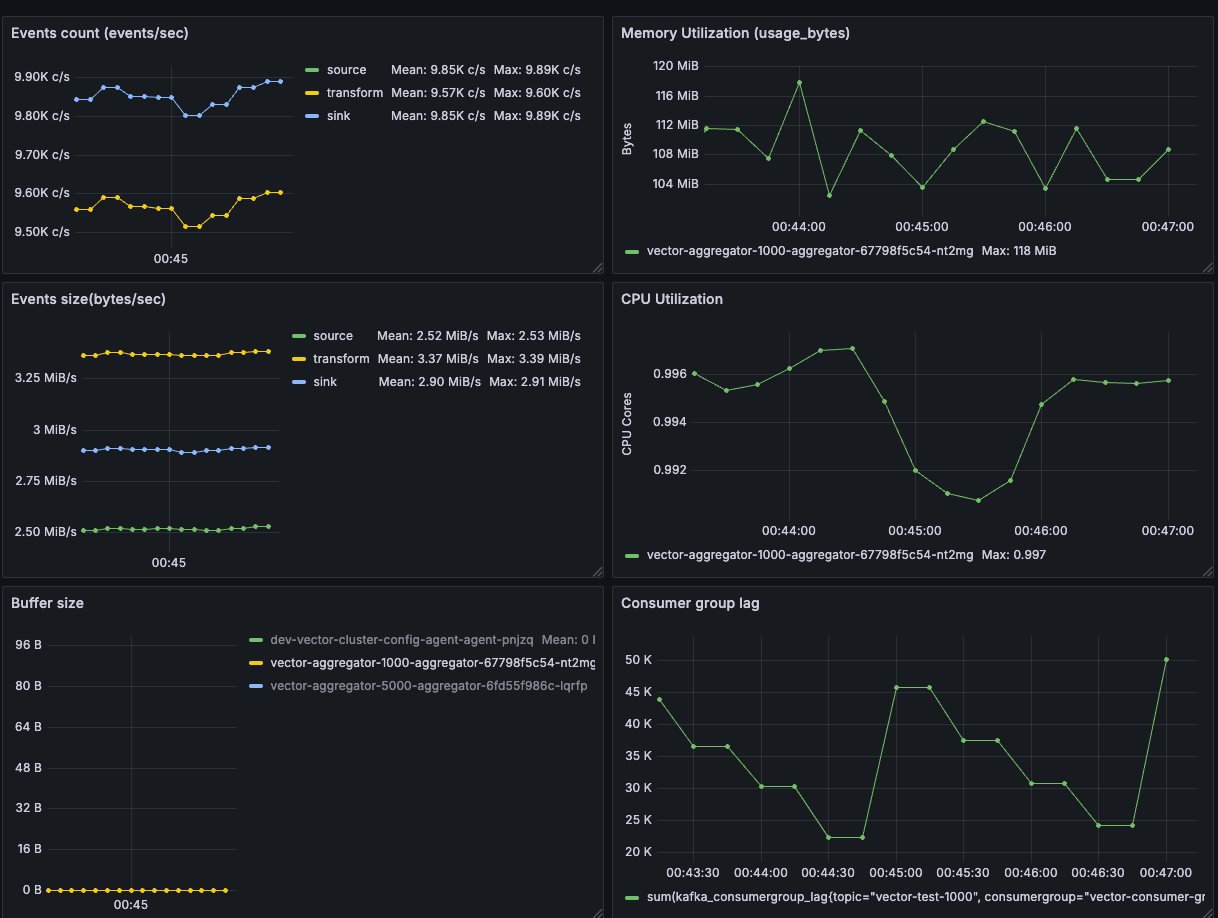
대시보드는 다음의 대시보드(19611)를 기반으로 만들었다. 대시보드는 이벤트 현황, CPU, 메모리, 버퍼 사용량과 Consumer Lag 수치를 보여준다.
Vector Cluster Monitoring - in Grafana Labs
초당 10,000개의 이벤트를 보냈을 때의 성능을 확인한 결과는 다음과 같다:
메모리는 약 100MB 내외로 사용되었으며, 버퍼는 사용하지 않았다. CPU는 1코어 정도로, 예상보다 많이 사용되지 않았다.
Consumer 그룹의 Lag은 5만 내외로 유지되었고, 배치 주기를 60초 또는 20MB로 설정한 상황에서, 데이터가 거의 실시간으로 적재되고 있다는 것을 확인할 수 있었다.
참고: VECTOR THREADS를 1로 설정했지만 PC CPU(?)에 따라 데이터가 약 10MB( 1/2 )씩 2개로 저장되었다.
POD 쉘 내부로 접속해 vector top 명령어를 실행하면 아래와 같은 화면을 확인할 수 있다. Grafana에서 보여준 수치와 일치한다.

간단 결론
로컬에서 테스트한 결과지만, MSK, EKS, S3를 활용해 AWS 내부에서 배포하더라도 비슷한 성능을 보일 것으로 예상된다.
기본적인 Kafka Consumer와 Amazon Data Firehose 기능을 성능적으로나 비용적으로 충분히 대체할 수 있을 것으로 보인다.
참고
grafana query
Events count :
sum by (component_kind) (rate(vector_component_received_events_total{component_kind="source", host=~"$pod"}[1m]))
Events size :
sum by (component_kind) (rate(vector_component_received_event_bytes_total{component_kind="source", host=~"$pod"}[1m]))
Buffer size :
sum by(host) (vector_buffer_byte_size{buffer_type="memory", host=~"$pod"})
Memory Utilization :
sum(container_memory_usage_bytes{namespace="platform", container!=""}) by(pod)
CPU Utilization :
sum(rate(container_cpu_usage_seconds_total{namespace="platform", container!=""}[$__rate_interval])) by(pod)
Consumer group lag :
sum(kafka_consumergroup_lag{topic="vector-test-1000", consumergroup="vector-consumer-group-1000"})
vector 배포 yaml
최소 성능 확인을 위해 VECTOR_THREADS를 1로 설정하였다.
VectorAggregator
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorAggregator
metadata:
name: vector-aggregator-1000
namespace: platform
spec:
image: timberio/vector:0.43.0-alpine
replicas: 1
env:
- name: VECTOR_THREADS
value: "1"
- name: VECTOR_LOG
value: "INFO"
- name: VECTOR_GRACEFUL_SHUTDOWN_LIMIT_SECS
value: "10"
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_SECRET_ACCESS_KEY
api:
enabled: true
internalMetrics: true
VectorPipeline
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorPipeline
metadata:
name: vector-pipeline-1000
namespace: platform
spec:
sources:
kafka_source:
type: "kafka"
bootstrap_servers: "dev-kafka-cluster-kafka-bootstrap.common.svc.cluster.local:9092"
topics:
- vector-test-1000
group_id: "vector-consumer-group-1000"
auto_offset_reset: "earliest"
# 신뢰성을 위한 설정
commit_interval_ms: 5000
decoding:
codec: json
transforms:
format_json:
inputs:
- kafka_source
type: remap
source: |
del(.topic)
del(.source_type)
del(.partition)
del(.offset)
del(.headers)
. = encode_json(.)
sinks:
s3_sink:
type: "aws_s3"
inputs:
- format_json
bucket: "vector-test"
endpoint: "http://common-minio-hl.common.svc.cluster.local:9000" # MinIO endpoint
region: "ap-northeast-2"
key_prefix: "logs_1000/dt=%Y-%m-%d/"
acknowledgements:
enabled: true # ACK 활성화
filename_append_uuid: true
filename_time_format: "%s"
compression: "none"
encoding:
codec: "text"
buffer:
type: "memory"
max_events: 50000
when_full: "block"
batch:
max_bytes: 20971520 # 20MB
timeout_secs: 60
python 테스트 코드
chatGPT를 활용해서 간단하게 작성하였다.
import time
import json
import random
import logging
import multiprocessing
from kafka import KafkaProducer
# MSK INFO
BOOTSTRAP_SERVERS = '172.30.1.103:9094'
KAFKA_VERSION = (3, 7, 1)
# 로깅 설정
logger = logging.getLogger()
logger.setLevel(logging.WARNING)
def on_send_error(err):
logger.error('[ERROR] : produce Failed', exc_info=err)
# KafkaProducer 설정 (각 프로세스마다 별도로 생성)
def create_producer():
return KafkaProducer(
bootstrap_servers=BOOTSTRAP_SERVERS,
api_version=KAFKA_VERSION,
acks='all',
retries=1,
security_protocol='PLAINTEXT',
key_serializer=lambda v: v,
request_timeout_ms=2000,
metadata_max_age_ms=5000
)
def send_messages(producer, topic, target_tps):
"""
지정된 TPS로 메시지를 전송
Args:
producer: Kafka 프로듀서 인스턴스
topic: 대상 토픽
target_tps: 목표 TPS (초당 전송량)
"""
interval = 1.0 / target_tps # 메시지 간 대기 시간
while True:
data = {
"device_id": f"sensor-{random.randint(1, 100)}", # 랜덤 센서 ID
"timestamp": time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()), # ISO 8601 UTC 시간
"location": {
"latitude": round(random.uniform(-90.0, 90.0), 6), # 위도 (-90 ~ 90)
"longitude": round(random.uniform(-180.0, 180.0), 6), # 경도 (-180 ~ 180)
"altitude": round(random.uniform(0, 5000), 2) # 고도 (0 ~ 5000m)
},
"data": {
"temperature": round(random.uniform(-20.0, 50.0), 2), # 온도 (-20°C ~ 50°C)
"humidity": round(random.uniform(0.0, 100.0), 2), # 습도 (0% ~ 100%)
"air_quality_index": random.randint(0, 500) # 공기질 지수 (0 ~ 500)
},
"battery_status": {
"level": random.randint(0, 100), # 배터리 잔량 (0% ~ 100%)
"charging": random.choice([True, False]) # 충전 여부
}
}
# Kafka에 메시지 전송
producer.send(topic, value=json.dumps(data, ensure_ascii=False).encode())
# TPS 제어를 위한 대기
time.sleep(interval)
def start_process(target_tps, topic):
"""멀티프로세싱용으로 send_messages 함수 실행"""
producer = create_producer() # 각 프로세스마다 독립적인 producer를 생성
send_messages(producer, topic, target_tps)
def run_multiprocessing(target_tps, topic, num_processes=4):
"""
멀티프로세싱으로 메시지 전송을 여러 프로세스에서 병렬로 실행
Args:
target_tps: 목표 TPS (초당 전송량)
topic: Kafka 토픽
num_processes: 실행할 프로세스 수
"""
# 여러 프로세스를 실행
processes = []
# 프로세스 생성
for _ in range(num_processes):
process = multiprocessing.Process(target=start_process, args=(target_tps, topic))
processes.append(process)
process.start()
# 모든 프로세스가 끝날 때까지 기다리기
for process in processes:
process.join()
if __name__ == "__main__":
topic = 'vector-test-1000'
target_tps = 2500
run_multiprocessing(target_tps, topic, num_processes=4)
References :