AWS EC2로 Hadoop Cluster 구축하기 - (1)
게시일 : 2019년 04월 01일
# AWS
# EC2
# Hadoop
Deploying a Hadoop Cluster Lesson 1을 기반으로 작성하였다.
Hadoop 2.9 Cluster를 AWS EC2 Instance로 구축해본다.
구축환경
- Local PC : Ubuntu 18.04
- NameNode 1 (+Secondary Namenode)
- DataNode 3
- EC2 Instance : Ubuntu 18.04 / t2.medium / 20GB
- Security Group : All traffic ( TEST 용으로)
- Elastic IP 사용
참고 : Elastic IP EC2에서 static IP를 사용하기 위함
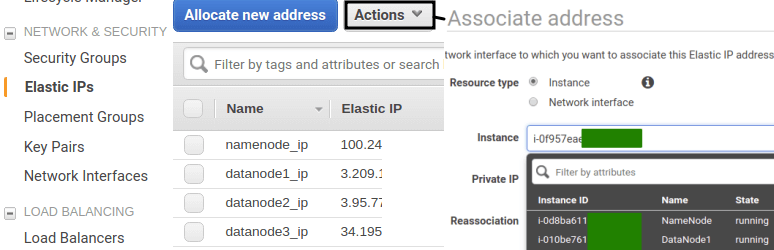
하둡 Node 기본 세팅
처음 생성한 Instance를 Namenode로 사용할 예정이다.
EC2 생성할 때 AWS에서 제공하는 private key(hadoop_cluster.pem)를 다운받는다.
Local PC(Ubutu)에서,
# private key는 소유자만 사용하도록 권한 설정부터 해야 사용할 수 있다.
sudo chmod 400 ~/hadoop_cluster.pem
## ls -l로 확인하면 -r------- 로 변한다.
# private key를 Instance로 ssh를 통해 복사
scp -i hadoop_cluster.pem hadoop_cluster.pem ubuntu@[Public DNS]:~/.ssh
# private key로 Instance 연결
ssh -i ~/hadoop_cluster.pem ubuntu@[Public DNS]
ssh 연결 후
hostname 변경
참고 : https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/set-hostname.html
Instance의 기본 hostname은 ip-000-00-00-00 이런 식으로 되어있다.
필수는 아니지만 나중에 환경설정을 편하게 하기 위해 hostname을 변경한다. (namenode와 datanode 각각 설정해야 한다.)
# 다음 명령 추가 실행 후 instance 재실행
sudo hostnamectl set-hostname namenode
sudo reboot
기본 설치
sudo apt update & sudo apt dist-upgrade -y
# JAVA 1.8 설치
sudo apt install openjdk-8-jdk
# 하둡 2.9.2 설치
wget http://apache.mirror.cdnetworks.com/hadoop/common/ \
hadoop-2.9.2/hadoop-2.9.2.tar.gz -P ~/Downloads
# 압축을 풀고 폴더 이름을 /usr/local/hadoop으로 간단하게 변경
sudo tar zxvf ~/Downloads/hadoop-* -C /usr/local
sudo mv /usr/local/hadoop-* /usr/local/hadoop
~/.bashrc에 환경설정 추가
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 참고 : JAVA 경로 확인 readlink -f $(which java)
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 저장 후
source ~/.bashrc
sudo chown -R ubuntu $HADOOP_HOME # 하둡 폴더 소유자 변경
모든 Node 기본 환경 설정
cd $HADOOP_CONF_DIR 후,
hadoop-env.sh
JAVA를 환경변수에 이미 설정했지만 hadoop이 인식못하는 것을 방지하기 위해서 추가로 설정한다.
# 아래 부분을 찾아서 고친다.
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
core-site.xml
<configuration>
# node에게 namenode의 정보를 알려준다.
<property>
<name>fs.defaultFS</name>
<value>hdfs://[Namenode의 Public DNS]:9000</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>[Namenode의 Public DNS]</value>
</property>
</configuration>
mapred-site.xml
# 먼저 mapred-site.xml 파일 생성
sudo cp mapred-site.xml.template mapred-site.xml
<configuration>
# jobtracker는 yarn을 사용하지 않을 경우를 대비한 용도
<property>
<name>mapreduce.jobtracker.address</name>
<value>[Namenode의 Public DNS]:54311</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
DataNode 생성을 위한 Image 생성
DataNode를 생성하기 위해 현재 Instance를 Image로 만들어서 사용한다.
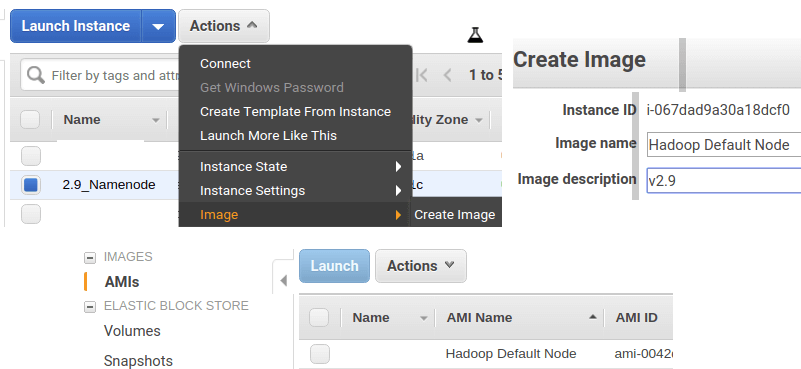
AMI 메뉴에서 launch를 선택하고 Instance를 3개 생성한다. Security Group과 key pair는 만들어 둔 값과 연결한다.
이어서, 다음 글로 이동
References :