AWS EC2로 Hadoop Cluster 구축하기 - (2)
게시일 : 2019년 04월 01일
# AWS
# EC2
# Hadoop
Deploying a Hadoop Cluster Lesson 1을 기반으로 작성하였다.
Hadoop 2.9 Cluster를 AWS EC2 Instance로 구축해본다.
NameNode와 DataNode 각각 설정하기
Local PC에서 모든 instance와 SSH 연결
~/.ssh/config
아래 설정을 하고나면 ssh namenode 이런 식으로 간편하게 접속이 가능하다.
# config 파일 생성
touch ~/.ssh/config
# private key ~/.ssh 폴더로 이동
mv ~/hadoop_cluster.pem ~/.ssh
Host namenode
HostName [Public DNS]
User ubuntu
IdentityFile ~/.ssh/hadoop_cluster.pem
Host datanode1
HostName [Public DNS]
User ubuntu
IdentityFile ~/.ssh/hadoop_cluster.pem
Host datanode2
HostName [Public DNS]
User ubuntu
IdentityFile ~/.ssh/hadoop_cluster.pem
Host datanode3
HostName [Public DNS]
User ubuntu
IdentityFile ~/.ssh/hadoop_cluster.pem
# 저장 후 namenode에도 이 파일을 복사한다.
scp ~/.ssh/config namenode:~/.ssh/config
datanode instance 각각 ssh 접속을 한 후 hostname 변경
NameNode 설정
ssh 설정
namenode가 비밀번호 없이 datanode에 접근하도록 하기 위함
ssh-keygen -f ~/.ssh/id_rsa -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# datanode에 public key를 인증
ssh datanode1 'cat >> ~/.ssh/authorized_keys' < ~/.ssh/id_rsa.pub
ssh datanode2 'cat >> ~/.ssh/authorized_keys' < ~/.ssh/id_rsa.pub
ssh datanode3 'cat >> ~/.ssh/authorized_keys' < ~/.ssh/id_rsa.pub
/etc/hosts
127.0.0.1 localhost
[namenode_Public DNS] namenode
[datanode1_Public DNS] datanode1
[datanode2_Public DNS] datanode2
[datanode3_Public DNS] datanode3
참고 : Public DNS 대신 private IP 사용을 해야 한다는 의견도 있다.
$HADOOP_CONF_DIR/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
# namenode 데이터를 저장하는 폴더
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/hdfs/namenode</value>
</property>
</configuration>
# 저장 후 입력한 폴더를 생성한다.
sudo mkdir -p $HADOOP_HOME/data/hdfs/namenode
$HADOOP_CONF_DIR/masters & slaves
masters는 secondary namenode의 위치를 지정한다.
여기서는 namenode와 같은 instance에 만들기 때문에 namenode의 hostname을 입력한다.
# masters 파일 직접 생성 후
namenode
slaves는 datanode들의 위치를 지정한다.
# localhost는 지우고 hostname으로 작성
datanode1
datanode2
datanode3
DataNode 설정 (모든 DataNode 각각 설정)
$HADOOP_CONF_DIR에서,
yarn-site.xml
intermediate data를 저장하기 위한 폴더를 설정해야 한다.
이 폴더를 설정하지 않으면, ‘exitCode=-1000. No space available in any of the local directories’ 이런 오류가 생길 수 있다.
# 내용 추가
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///usr/local/hadoop/yarn/local</value>
</property>
# 저장 후 해당 폴더 생성
mkdir -p /usr/local/hadoop/yarn/local
참고 : Error 해결 방법
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/hdfs/datanode</value>
</property>
</configuration>
# 저장 후 해당 폴더 생성
mkdir -p /usr/local/hadoop/data/hdfs/datanode
Hadoop Cluster 실행하기
namenode에서
hdfs namenode -format # namenode format (오류없이 shutdown 표시가 나오면 됨)
start-dfs.sh # HDFS 실행
start-yarn.sh # YARN 실행
mr-jobhistory-daemon.sh start historyserver # job history server 실행
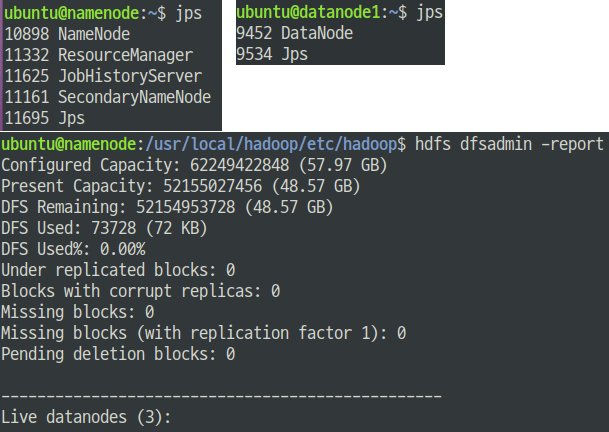
각 Node에서 jps를 실행해보면 확인할 수 있다. (datanode는 최초에만 확인 가능)
또한, HADOOP UI(:50070)과 YARN UI(:8088)을 통해서 확인할 수도 있다.
# home directory 생성
hdfs dfs -mkdir -p /user/ubuntu
# Sample Test
## create random-data
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/
hadoop-mapreduce-examples-*.jar teragen 500000 random-data
## sort
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/
hadoop-mapreduce-examples-*.jar terasort random-data sorted-data
instance를 중지시킬 경우에는 모든 프로세스를 먼저 종료해야 한다.
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
Datanode가 제대로 실행되지 않은 경우 재구축 방법
namenode에서
# 모든 프로세스 종료
rm -rf /usr/local/hadoop/data/hdfs/namenode/*
# reboot 불필요
datanode에서
rm -rf /usr/local/hadoop/data/hdfs/datanode/*
rm -rf /usr/local/hadoop/yarn/local/*
sudo reboot
다시 hdfs namenode -format부터 실행하면 된다.